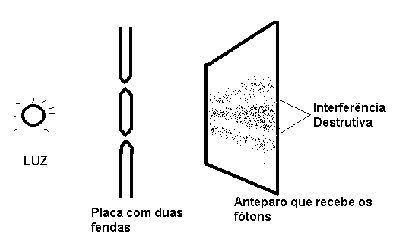
FIGURA 2.1 – Experimento das duas fendas. Os pontoes escuros são os pontos onde os fótons precipitam. Observe as regiões claras horizontais onde encontramos interferência destrutiva.
UNIVERSIDADE FEDERAL DO RIO GRANDE DO SUL
INSTITUTO DE INFORMÁTICA
CURSO DE PÓS-GRADUAÇÃO EM CIÊNCIA DA COMPUTAÇÃO
por
JOÃO PAULO SCHWARZ SCHÜLER
T.I. n. 956 CPGCC-UFRGS
Trabalho Individual I
Prof. Luis Otávio Campos Alvares
Orientador
Porto Alegre, dezembro de 2000.
SUMÁRIO
Lista de Abreviaturas 3
Resumo 6
Abstract 7
1 Introdução 8
1.1 Máquina como Sistema Físico 8
1.2 Assuntos Abordados 8
2 Computação Quântica 10
2.1O Experimento das Duas Fendas 10
2.1.1 Apresentação do Experimento 10
2.1.2 Interferência Destrutiva 10
2.1.3 O Estado Quântico 12
2.1.4 Amplitude de Probabilidade Complexa 13
2.2 O Princípio da Computação Quântica 14
2.2.1 Qubits ou Bits Quânticos 14
2.2.2 Notação 14
2.2.3 Correlação 15
2.2.4 Interações Locais e Não Locais 16
2.3 Quantum Computing Language 17
2.3.1 Introdução 17
2.3.2 Introdução à linguagem QCL 18
2.3.3 Primeiros Passos em QCL 18
2.3.4 Gerando Números Realmente Aleatórios 20
2.3.5 XOR em QCL 20
2.3.6 Teste de Igualdade 21
2.3.7 Informação e Qubits 22
2.3.8 Medindo a Solução Desejada 22
3 Computação Biológica 24
3.1 Evolução Biológica 24
3.1.1 Introdução 24
3.1.2 Resumo da Evolução da Vida na Terra 24
3.1.3 A Heurística da Evolução 26
3.1.4 Um Algoritmo Evolutivo Quântico 27
3.1.5 Fundamentos de Codificação Genética 27
3.1.6 DNA e Técnicas de Programação 28
3.2 Computação Molecular 30
3.2.1 Introdução 30
3.2.2 Modelo Abstrato 30
3.2.3 Exemplo de Aplicação 31
3.2.3.1 Objetivo 31
3.2.3.2 Definição do Algoritmo 31
3.2.3.3 Explicação do Funcionamento 32
4 Especulações 34
4.1 Computação Quântica e Biológica 34
4.1.1 Introdução 34
4.1.2 Replicação do DNA 34
4.1.3 Simulando a Pesquisa Quântica de Bases A,C,G,T 34
4.1.4 Comentários Finais 36
4.2 A Física Quântica e a Física do Cérebro 36
4.2.1 Introdução 36
4.2.2 Opinião de Henry P. Stapp 36
4.2.2.1 Descrição Intrínseca 36
4.2.2.2 Descrição Extrínseca 37
4.2.2.3 O Computador Cérebro 37
4.2.2.4 Comentários do Autor 37
4.2.3 Opinião de Stanley A. Klein 38
4.2.3.1 Comentários do Autor 38
4.3 Poder Computacional das Máquinas Quânticas e Biológicas 38
5 Conclusões 40
5.1 Colorabilidade de Grafo em Máquina Quântica 40
5.1.1 Estrutura de Dados 40
5.1.2 Implementação 41
5.1.3 Explicação do Funcionamento 41
5.2 Conclusões Finais 41
ANEXO I - Biblioteca boolean.qcl 43
Introdução 43
Função quAnd 43
Função quNand 43
Função quOr 44
Função quNor 44
Função quXor 44
Função quEqual 45
Função quTest 45
Operador quPICPhase 45
Função quVectNAnd 46
Função quVectNOr 46
Função quVectOr 46
ANEXO II -SAT em QCL 48
Introdução 48
Problemas Tratáveis e Intratáveis 48
Problema SAT 48
Implementação 48
Bibliografia 50
IA inteligência artificial
DNA ácido desoxirribonucléico
fig. . figura
UCP unidade central de processamento
UPF unidade de ponto flutuante
PC computador pessoal
QCL quantum computer language
E/S estrada e saída
Lista de Figuras
FIGURA 2.1 - Experimento das duas fendas 10
FIGURA 2.2 - Interferência destrutiva com ondas de mesma freqüência em fase. 11
FIGURA 2.3 - Interferência construtiva com ondas de mesma freqüência em oposição de fase. 11
FIGURA 2.4 - Experimento de uma fenda. Os pontos escuros são os pontos onde os fótons precipitam. 12
Lista de Tabelas
TABELA 2.1 –Usando o comando CNot para cópia 21
TABELA 2.2 –Usando o CNot como operação XOR.. 21
TABELA 3.1 – Bases encontradas no código genético. 27
TABELA 3.2 – Enzimas de restrição e DNAs virais. 29
TABELA 4.1 – Bases e autoestados correspondentes. 35
TABELA 4.2 –Pares e autoestados correspondentes. 35
TABELA 5.1 –Cores e autoestados correspondentes. 41
A computação é algo que ocorre em dispositivos físicos. O presente texto estuda dois tipos de computação baseados em processos de existência física bem distintos: computação quântica e computação biológica.
A computação quântica baseia-se na física de partículas. Uma única partícula quântica pode representar uma quantidade muito grande de bits permitindo processamento de informação massivamente paralelo. Por outro lado, a computação biológica baseia-se na química orgânica usando moléculas de DNA para processar informação. Considerando que cada molécula de DNA pode tomar parte em uma computação isolada, um tubo de ensaio contendo uma quantidade enorme de moléculas pode ser um sistema computacional de processamento massivamente paralelo.
Por fim, considerando-se que tanto a computação quântica como a computação
biológica são computações que transcorrem de forma massivamente paralela, pode-se
traçar paralelos entre as mesmas.
Palavras-chaves: computação quântica, computação molecular, computação biológica.
Computation is something that happens on physical devices. The present text studies two kinds of computation based on clear distinct physical processes: quantum computation and biological computation.
The quantum computation is based on physics of particles. Just one quantum particle can represent a large number of bits making it possible to process information on a massive parallel way. Biological computation is based on the organic chemistry using DNA molecules in order to process information. Considering that each DNA molecule can take part in one isolated computation, a test tube containing a large number of molecules can be a massive parallel computational processing system.
To finish, considering that quantum computation and biological computation
are kinds of massive parallel computation, it is possible find many common properties
on both kinds of computations.
Keywords: quantum computing, molecular computing, biologic computing.
A computação ocorre ao longo do espaço e do tempo[WIL 97]. Sendo assim, a questão sobre o que pode ser computado depende do que pode ser fisicamente construido[AHA 98]. Não adianta construir um formalismo lógico que represente uma máquina capaz de realizar computações se esta máquina não representa uma realidade física. Sendo assim, estudaremos física, química e biologia para inferir sobre novas formas de computação e suas aplicações para a inteligência artificial.
O primeiro cientista que observou que a mecânica quântica poderia ter significado computacional foi Richard Feynman. Feynman sugere que todo sistema físico pode ser simulado por um computador exatamente e sem ruído algum. Feynman sugere ainda que: (1) o espaço e o tempo são discretos e não contínuos; (2) o universo físico é baseado em mecânica quântica; (3) simular um sistema físico é simular um sistema quântico[FEY 82]. Supondo que para todo sistema físico existe uma computação equivalente, então todo sistema físico realiza uma computação.
David Deutsch propôs que máquinas usando mecânica quântica poderiam realizar computações eficientes para problemas que máquinas clássicas poderiam realizar somente de forma extremamente ineficiente[DEU 85].
No capítulo 2, rompe-se com a entendimento clássico do mundo físico. Serão abordados aspectos como partículas deslocalizadas que de certa forma existem em diferentes pontos do espaço ao mesmo tempo e se apresentam em superposição de estados distintos. Para o leitor que nunca estudou física quântica, o capítulo 2 será no mínimo chocante. A física quântica nega a percepção do mundo observada na escala do que os olhos dos seres humanos podem observar.
Fazendo uso da física quântica, a computação quântica abre possibilidade para resolver problemas extremamente custosos em termos de CPU de forma rápida [BAR 96] [BER 93]. Por efeito de simplicidade, será abordado um simulador de máquina quântica e serão desenvolvidos algoritmos para a máquina quântica simulada. O autor do presente trabalho desenvolveu formas simples de executar funções lógicas na máquina quântica simulada.
No capítulo 3, defende-se a idéia de que a evolução biológica é um processo de otimização sobre a informação genética. Entendendo-se que a evolução da biologia é um processo de otimização e que a maior parte da história da reprodução na biologia é assexuada, ao contrário dos algoritmos genéticos, propõem-se o uso de um algoritmo evolutivo assexuado.
A evolução biológica escolheu as moléculas de DNA para armazenar e processar a informação genética. Em princípio, pode-se fazer computação ao nível de moléculas orgânicas e inorgânicas; porém, diversos dispositivos genéticos teóricos e tecnológicos já foram desenvolvidos pela biologia. Sendo assim, o modelo de computação molecular estudado aqui é baseado em moléculas de DNA. Os processos sobre a informação do DNA servirão como fonte de inspiração para construção de modelos de computação molecular.
É interessante observar o fato de que Richard Feynman é citato como visionário da computação molecular [ADL 94] e como visionário da computação quântica [SIM 94]. Conforme a conclusão, a computação quântica e a computação biológica são indicadas para resolver a mesma classe de problemas.
Estudaremos o experimento das duas fendas tendo em vista que ele proporcionará base matemática e teórica para o leitor entender princípios fundamentais da computação quântica. O experimento das duas fendas foi largamente estudado na bibliografia [PEN 89] [HAW 88] [HAL 94] e serve de porta de entrada para entendermos o comportamento do elétron, do fóton e de outras partículas.
O experimento das duas fendas pode ser descrito como segue: uma lâmpada monocromática emite fótons que incidem sobre uma placa totalmente opaca que possui duas fendas paralelas. Posteriormente à placa de duas fendas paralelas, encontra-se um anteparo onde pode-se observar a precipitação dos fótons que conseguem passar pelas fendas da placa intermediária. O experimento de uma fenda é idêntico ao experimento de duas fendas; porém, o experimento de uma fenda possui uma placa intermediária com somente uma fenda.
Conforme esperado, no anteparo que recebe os fótons que ultrapassam as duas fendas, em algumas regiões, observa-se que a quantidade de fótons que precipitam sobre o anteparo é o dobro da quantidade que encontramos quando somente existe uma fenda na placa intermediária (ver figuras 2.1 e 2.4). Porém, no experimento das duas fendas, de forma contrária à física clássica, observamos regiões que recebem menos fótons do que no experimento de uma fenda! Como?
FIGURA 2.1 – Experimento das
duas fendas. Os pontoes escuros são os pontos onde os fótons precipitam. Observe
as regiões claras horizontais onde encontramos interferência
destrutiva.
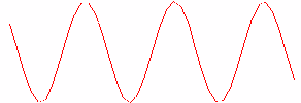
Para o anteparo que recebe os fótons, as fendas são as fontes de fótons. A fonte monocromática garante que a freqüência de onda dos fótons seja a mesma. Observe que existem pontos no anteparo que estão a distâncias diferentes de cada uma das fendas. Sendo assim, existem pontos que receberão as ondas de luz com mesma freqüência em oposição de fase. Como pode ser visto na figuram 2.2, ondas de mesma freqüência em oposição de fase se anulam mutuamente. Essa soma de ondas de mesma freqüência em oposição de fase é chamada de interferência destrutiva. Em capítulos posteriores, serão apresentadas computações que se anulam por interferência destrutiva.
Ao contrário da interferência destrutiva, a interferência construtiva é a soma de ondas com a mesma freqüência e mesma fase. Podemos ver na figura 2.3 um exemplo de interferência construtiva. Assim como serão apresentadas computações que se interferem destrutivamente, serão apresentadas computações que se interferem construtivamente.

+
=![]()
FIGURA 2.2 - Interferência destrutiva com ondas de mesma freqüência em
fase.

+
=
FIGURA 2.3 - Interferência construtiva com ondas de mesma freqüência em
oposição de fase.
Baseando-se na física clássica, o leitor pode imaginar que se a lâmpada emitir apenas um fóton de cada vez, não teremos interferência destrutiva no anteparo. Experimentalmente, observa-se que mesmo emitindo um fóton de cada vez encontra-se interferência destrutiva[HAL 94]! Por que um único fóton sofre interferência destrutiva quando passa pela placa de duas fendas? Pode-se explicar esse fato tendo em vista que o mesmo fóton passa por todos os caminhos possíveis ao mesmo tempo enquanto se desloca! O fóton passa pelas duas fendas ao mesmo tempo e pode sofrer interferência destrutiva de si próprio! O mesmo fóton pode percorrer caminhos distantes de vários anos luz. Cada caminho que o fóton percorre é uma alternativa. O estado do fóton é função da superposição das suas alternativas [PEN 89].
O fato de que a mesma partícula pode existir ao mesmo tempo em lugares diferentes nega violentamente a intuição humana. Por que os sentidos humanos nunca evidenciaram que o mesmo corpo existe ao mesmo tempo em lugares diferentes? Roger Penrose [PEN 89] apresenta uma resposta: o nível quântico é o nível das moléculas, átomos, elétrons, fótons e partículas subatômicas. No nível quântico, o estado das partículas é descrito pela superposição de suas alternativas. Quando uma das alternativas desencadear a liberação de energia superior a um gráviton, apenas uma alternativa sobrevive enquanto que as outras alternativas desaparecem. A determinação da alternativa que sobreviverá é probabilística sendo que a probabilidade de sobrevivência de cada alternativa é o módulo quadrado de sua amplitude de probabilidade. Durante a propagação de sinais visuais, os nervos óticos do sistema nervoso humano liberam energias muito superiores a um gráviton. Sendo assim, a percepção humana de um evento destruirá a superposição de alternativas.
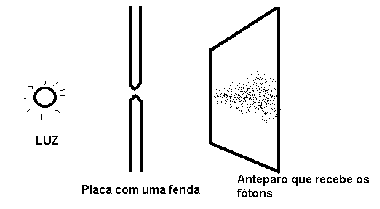
FIGURA 2.4 - Experimento de
uma fenda. Os pontos escuros são os pontos onde os fótons precipitam. Não
observa-se interferência destrutiva.
A percepção humana percebe apenas eventos de nível clássico ( não quântico ). Sendo assim, se queremos construir máquinas baseadas em mecânica quântica, elas deverão ficar isoladas da percepção humana ou qualquer outro evento que provoque geração de energia superior a um gráviton enquanto trabalham. A percepção humana ou outro tipo de medição deverá ser feito apenas ao final do trabalho da máquina quântica. No presente texto, entende-se por máquina quântica uma máquina que use mecânica quântica e que durante seu funcionamento apresente estados quânticos.
Para efeito de exemplo, imagina-se um sistema feito por uma caixa e uma bola sendo que a bola ou está dentro da caixa ou está fora da caixa. A bola não pode estar ao mesmo tempo dentro e fora da caixa. O conjunto de estados que a bola pode ter é “dentro da caixa” ou “fora da caixa”. Sendo assim, a bola pode estar em um de dois estados mutuamente exclusivos. Pode-se entender que o estado em que a bola está “dentro da caixa” é o estado zero (0) e que o estado em que a bola está “fora da caixa” é o estado um (1). Sendo assim, os estados 0 e 1 são mutuamente exclusivos. Os estados 0 e 1 são mutuamente exclusivos porque a física clássica a qual a bola esta presa não permite superposição dos estados “dentro da caixa” e “fora da caixa”.
Continuando o raciocínio do parágrafo anterior, substituindo a bola por um elétron, um elétron pode estar “dentro da caixa” e “fora da caixa” ao mesmo tempo. Sendo assim, o estado do elétron pode ser 0 e 1 ao mesmo tempo. O estado do elétron é uma superposição linear dos estados básicos (autoestados) 0 e 1. O estado quântico é o estado que partículas de nível quântico apresentam como superposição linear de estados básicos.
Anteriormente, observamos que a percepção humana destrói a superposição de alternativas ( autoestados ou estados básicos ) de uma partícula porque gera mais energia do que a energia de um gráviton. Chamaremos de medição o transporte de informação do nível quântico para o nível clássico. Durante a medição, a energia de um gráviton é superada. Sendo assim, a partícula perderá a superposição linear de autoestados. Durante a medição, a partícula quântica que é medida sofre uma transição de estado saindo da superposição linear de autoestados para remanescer em apenas um dos seus autoestados. Essa perda de superposição linear de autoestados é chamada de colapso do vetor de autoestados.
Voltando ao problema das duas fendas, vamos supor que existam medidores nas fendas para detectar a passagem dos fótons. Vamos supor ainda que um fóton é lançado da lâmpada por vez. Sabendo que eventualmente o mesmo fóton passa pelas duas fendas ao mesmo tempo, os detectores (medidores) deveriam detectar ao memo tempo a passagem do fóton pelas duas fendas. Isso não ocorre porque a medição destrói a superposição linear de autoestados. Sendo assim, os detectores de fótons das fendas serão disparados um a cada vez e a interferência destrutiva observada no anteparo desaparecerá [PEN 89]!
Suponha-se que a precipitação de um fóton proveniente da fenda
A sobre o anteparo possua probabilidade p(a) e a precipitação de um fóton proveniente
da fenda B possua probabilidade p(b). Na física clássica, poderíamos supor que
a soma das probabilidades de dois eventos A e B é certamente maior que a probabilidade
de cada um dos mesmos tal que:![]() e
e ![]() . Onde fótons provenientes da fenda A
e da fenda B em oposição de fase se anulam mutuamente, o experimento das duas
fendas mostra um caso em que: p(a) > 0 e p(b) >0 e p(a)
+ p(b) = 0. De alguma forma, durante a interferência destrutiva, as probabilidades
anulam-se mutuamente. Para entender essa estranha propriedade da mecânica quântica,
estudaremos amplitudes de probabilidade mensuradas por números complexos.
. Onde fótons provenientes da fenda A
e da fenda B em oposição de fase se anulam mutuamente, o experimento das duas
fendas mostra um caso em que: p(a) > 0 e p(b) >0 e p(a)
+ p(b) = 0. De alguma forma, durante a interferência destrutiva, as probabilidades
anulam-se mutuamente. Para entender essa estranha propriedade da mecânica quântica,
estudaremos amplitudes de probabilidade mensuradas por números complexos.
A amplitude de probabilidade do estado de uma partícula quântica
é um número complexo. Para entender melhor, voltando ao experimento das duas
fendas, a probabilidade no nível clássico é o quadrado do módulo da amplitude
de probabilidade. Vale lembrar que o módulo do número complexo z=x+iy
é |z| = ![]() . Para efeito de exemplo, podemos calcular
sobre uma partícula que possui amplitude de probabilidade para o estado K com
valor de 0.3 + 0.4i ou (0.3 + 0.4i)|K> :
. Para efeito de exemplo, podemos calcular
sobre uma partícula que possui amplitude de probabilidade para o estado K com
valor de 0.3 + 0.4i ou (0.3 + 0.4i)|K> :
o módulo da amplitude de probabilidade é:
![]()
o quadrado do módulo da amplitude de probabilidade é 0.25. Isso significa que a partícula em medição possui uma probabilidade de ser medida no estado K de 0.25.
Assim como no nível clássico, onde o somatório das probabilidades não pode ultrapassar 1, em um sistema quântico, o somatório dos quadrados dos módulos das amplitudes de probabilidades não pode ultrapassar 1.
Módulos de amplitudes de probabilidade são sempre positivos;
porém, amplitudes de probabilidade podem ser negativas. Voltando ao problema
das duas fendas, supondo um ponto do anteparo em que a amplitude de probabilidade
de um fóton precipitar proveniente da fenda A seja ![]() e a amplitude de probabilidade de o mesmo
fóton precipitar sobre o anteparo proveniente da fenda B seja
e a amplitude de probabilidade de o mesmo
fóton precipitar sobre o anteparo proveniente da fenda B seja ![]() . Sendo assim, a soma das duas amplitudes
de probabilidades é zero indicando interferência destrutiva. Por outro lado,
o somatório dos quadrados dos módulos das amplitudes de probabilidades é 1.
. Sendo assim, a soma das duas amplitudes
de probabilidades é zero indicando interferência destrutiva. Por outro lado,
o somatório dos quadrados dos módulos das amplitudes de probabilidades é 1.
Por que estudar física quântica se queremos apenas construir e programar computadores? Os computadores existem físicamente no espaço e no tempo. Os computadores fazem o que a física permite. O estado de cada bit de nossos computadores corresponde a um estado físico de nossa máquina. Tendo entendido o comportamento dos estados quânticos poderemos construir computadores que processam bits quânticos.
Um bit clássico pode estar somente em um de dois estados básicos mutuamente exclusivos. Ao contrário, um bit quântico pode estar em uma superposição de estados básicos. Voltando ao sistema em que o elétron pode estar dentro e fora da caixa ao mesmo tempo, supondo que o elétron tem uma amplitude de probabilidade Z de estar dentro da caixa ( estado zero ou |0> ) e uma amplitude de probabilidade W de estar fora da caixa ( estado um ou |1> ), descreveremos o estado do elétron na forma como segue: Z|0> + W|1> que deve ser entendido como superposição linear dos autoestados zero e um com amplitudes de probabilidade Z e W respectivamente. Vale observar que |Z|² + |W|² = 1. O estado de um bit quântico é a superposição linear de seus autoestados.
O estado de um conjunto de dois bits quânticos pode ser descrito pela seguinte superposição linear de autoestados: x|00> + y|01> + z|10> + w|11> em que |x|² + |y|² + |z|² + |w|² =1. Apenas por lembrete, x,y,z e w são amplitudes de probabilidade complexas. Bits quânticos são chamados de qubits. Um conjunto de N qubits pode apresentar um estado que é superposição linear de 2N autoestados. De certa forma, um conjunto de N qubits pode estar em 2N estados diferentes ao mesmo tempo.
O estado dos bits de uma máquina clássica ou quântica deve ter uma correspondência física. Nenhuma das diversas fontes de consultas propôs a construção de máquinas quânticas baseadas em elétrons dentro ou fora de caixas. Por outro lado, podemos encontrar na bibliografia propostas para construção de máquinas quânticas em que o estado dos qubits corresponde ao spin de elétrons. O spin de um elétron pode ser -1/2 ou +1/2. Sendo assim, o spin de um elétron pode ser descrito pela superposição de autoestados: c1| -1/2 > + c2| +1/2 >. Substituindo-se -1/2 e +1/2 por 0 e 1 respectivamente, encontra-se: c1|0> + c2|1> sendo que c1 e c2 são amplitudes de probabilidade.
O bit quântico ou qubit é representado por um sistema quântico de dois estados que é constituído por apenas uma partícula. Um sistema quântico de dois estados é descrito por um vetor unitário complexo no espaço de Hilbert C2. O espaço de Hilbert é um espaço vetorial complexo. Os dois estados do sistema quântico são representados por: |0> e |1>. O estado |0> é representado pelo vetor complexo (1,0) em C2 enquanto que o estado |1> é representado pelo vetor (0,1). Os vetores (1,0) e (0,1) ou |0> e |1> constituem a base ortogonal no espaço de Hilbert[AHA 98].
Apenas para efeito de exemplo, abordaremos um registrador quântico de 3 qubits. Esse registrador é representado pela superposição linear de seus oito autoestados como segue:
c1|000> + c2|001> + c3|010> + c4|011> + c5|100> +c6|101> + c7|110> + c8|111>.
Para efeito de notação, consideremos:
x1 = |000>, x2 = |001>, x3 = |010>
... x8 = |111>. Lembrando que c1..c8 são
amplitudes de probabilidade, ![]() =1. O estado de um registrador quântico
de n qubits é a superposição linear de 2n autoestados. Uma superposição
uniforme de autoestados é uma superposição linear de estados onde todos os autoestados
apresentam a mesma amplitude de probabilidade. A superposição uniforme de autoestados
pode ser descrita como:
=1. O estado de um registrador quântico
de n qubits é a superposição linear de 2n autoestados. Uma superposição
uniforme de autoestados é uma superposição linear de estados onde todos os autoestados
apresentam a mesma amplitude de probabilidade. A superposição uniforme de autoestados
pode ser descrita como:
![]()
Uma operação f feita sobre um registrador quântico que apresenta superposição uniforme de autoestados pode ser descrita como:
![]()
Apenas para efeito de exemplo, apresentaremos a operação de incremento f:
f (c1 |000> + c2|001> + c3|101>) => c1 |001> + c2 |010> + c3 |110> .
No exemplo anterior, de certa forma, foram feitos três incrementos em paralelo usando apenas um único registrador quântico de três qubits.
Por fim, abordaremos um exemplo com o operador de negação NOT [AHA 98]:
NOT |0> = |1>
NOT |1> = |0>
NOT( c1|0> + c2|1> ) = c1|1> + c2|0>
NOT( c1|001> + c2|111> ) = c1|110> + c2|000>
A correlação ( do inglês, entanglement ) de estados surge naturalmente entre a interação entre partículas. No presente parágrafo, vamos supor que o estado inicial de duas partículas correlacionadas é o que segue: c1|00> + c2|11>. Vamos supor ainda que resulta da medição da primeira partícula o estado |0>. Por estarem correlacionadas as duas partículas, com a medição da primeira partícula, o vetor de estados do sistema composto pelas duas partículas entra em colapso caindo no estado |00>. Sendo assim, a medição sobre uma partícula de um sistema de partículas correlacionadas provoca o colapso de estado de todo o sistema de partículas imediatamente mesmo que as partículas estejam separadas por vários anos luz.
Considerando o exemplo do parágrafo anterior, se, por acaso, a medição da primeira partícula resultasse em |1>, então o estado da segunda cairia obrigatoriamente no estado |1>. A segunda partícula simplesmente não poderia ser fisicamente medida no estado |0> tendo em vista que não existe um estado c3|10> inicial.
A informação quântica é extremamente frágil. É impossível
impedir iterações entre um sistema quântico e o ambiente em que está inserido.
Essa iteração provoca perda na natureza quântica em um processo chamado de
decoerência [AHA 98]. Para manter a computação coerente, é necessário isolar os
registradores quânticos impedindo que else se correlacionem com o ambiente [OME
88]. A decoerência é uma questão de tempo. Quanto maior for o espaço de tempo
envolvido, maiores serão as chances de verificarmos decoerência.
Para
manter a computação coerente, os registradores quânticos não podem dissipar
calor. A dissipação de calor provocaria a correlação entre o registrador
quântico e o ambiente causando decoerência. Sendo assim, a entropia do sistema
de computação quântica não pode crescer. Lembrando que a entropia é incrementada
nos processos irreversíveis, a computação quântica é reversível e adiabática
[OME 88].
As interações locais são as interações que estamos acostumados na física clássica e na física relativista. Uma interação local é uma interação que envolve contato direto ou uma interação com um meio intermediário que provoca interação por contato direto com um meio físico final. As interações de contato direto são as interações que estamos acostumados nas nossas vidas. A gravidade, a percepção de ondas eletromagnéticas pelos nossos aparelhos de televisão e troca de calor entre corpos são exemplos de interações locais. As ondas eletromagnéticas se propagam no vácuo a velocidade da luz perdendo energia a medida que se afastam da fonte.
Interações locais não são interações que ocorrem entre corpos próximos. O emissor e receptor de uma mesma onda eletromagnética podem estar separados por vários anos luz sendo que o tempo de propagação do sinal entre o emissor e o receptor é necessariamente igual ou superior ao tempo de propagação da velocidade da luz no vácuo. As interações locais podem ser verificadas entre corpos separados por distâncias arbitrariamente grandes.
A força gravitacional é uma interação local porque é mediada por partículas chamadas grávitons que viajam entre elementos que gravitam. Assim como os fótons, os grávitons não podem viajar acima da velocidade da luz.
Considerando exclusivamente as interações locais, se dois eventos ocorrem a uma distância de espaço e tempo de forma que mesmo viajando a velocidade da luz o efeito de um evento não pode alcançar o outro, podemos afirmar que os eventos estão espacialmente separados ( do inglês, spacelike separated ).
De forma geral, podemos caracterizar as interações locais da forma como segue: (1) podem ser intermediadas por outras entidades como partículas ou campos; (2) não se propagam mais rápido que a velocidade da luz; (3) a sua influência diminui com a distância.
As forças eletromagnéticas, gravitacionais, nucleares fortes e fracas são responsáveis por interações locais. Sendo assim, todas as quatro forças conhecidas do universo produzem somente interações locais. De onde vêm as interações não locais?
Nos parágrafos anteriores não discutimos o colapso do vetor de autoestados. Durante a medição, o vetor de autoestados de um sistema de partículas correlacionadas sofre o colapso de autoestados. O colapso do vetor de estados não envolve força de nenhum tipo. Lembrando que o colapso do vetor de autoestados pode interferir em partículas correlacionadas divididas por diversos anos luz de forma imediata, podemos observar uma grande diferença entre interação que ocorre durante o colapso do vetor de auto estados e as interações provocadas pelas quatro forças físicas conhecidas. As interações provocadas pelas quatro forças do universo conhecidas dependem da velocidade de propagação luz enquanto que a interação provocada pelo colapso do vetor de autoestados não depende de propagação de sinais a velocidade da luz e nem de um meio conhecido para propagar seus sinais.
Não é fácil definir o que as interações não locais são. É mais fácil definir o que elas não são: (1) não são intermediadas por outras entidades; (2) não dependem da velocidade da luz; (3) a sua influência não diminui com a distância. O colapso do vetor de autoestados é um tipo de interação não local.
O presente tópico foi escrito com base na seção 9.3 do livro Explorations in Quantum Computing [WIL 97].
Por que simular computadores quânticos em máquinas convencionais? Simulando computadores quânticos poderemos ter uma idéia das dificuldades a serem enfrentadas no desenvolvimento de novos algoritmos destinados a computadores quânticos. É interessante observar que antes do primeiro computador quântico ser construído, teremos diversos algoritmos específicos para computadores quânticos rodando em simulação. Além disso, através de simulações, teremos uma idéia muito aproximada do que poderemos esperar ao construir computadores quânticos.
Em geral, vale a pena simular um sistema quando a simulação é imensamente menos custosa e ainda assim permite estudarmos os aspectos de interesse do sistema real. Esse é exatamente o motivo pelo qual trabalharemos com simuladores de máquinas quânticas.
Existem diversos pacotes para simulação de computadores quânticos. No entendimento do autor do presente texto, os mais interessantes são Open Qubit [OPE 2000] e QCL ( Quantum Computer Language)[OME 88][OME 2000]. A maior desvantagem do Open Qubit frente ao QCL é a sua dificuldade de operação tendo em vista que o Open Qubit é uma biblioteca C. Sendo assim, Open Qubit exige muito de seu usuário para implementar seus primeiros programas simples. Por ser interpretada, a linguagem QCL permite que seu usuário entre com comandos e funções de forma iterativa e ainda verifique o estado de cada registrador da máquina virtual. O QCL é ideal para o ensino de linguagem de programação de computador quântico.
O QCL prevê uma máquina híbrida composta por uma máquina clássica semelhante aos bem conhecidos PCs e uma máquina de estados quânticos. O usuário se comunica somente com a máquina clássica. A máquina clássica requisita operações e medições à máquina de estados quânticos. Traçando uma analogia, os PCs modernos possuem unidades de ponto flutuante (UPF) integradas à CPU. Os comandos de salto e controle não pertencem a UPF. A UPF apenas realiza as instruções relativas as operações de ponto flutuante. Da mesma forma, o QCL prevê uma máquina clássica que realiza os testes, desvios, E/S e possui registradores convencionais em contato com uma máquina de estados quânticos que realiza as operações quânticas.
O presente texto não é um tutorial de QCL. Se o leitor desejar aprofundar-se na linguagem QCL existe excelente bibliografia [OME 88] [OME 2000] sobre o assunto.
Para efeito de exemplo, consideraremos o programa QCL que segue:
int Teste() {
int i; // aloca uma variável inteira na máquina clássica
int d; // aloca uma variável inteira na máquina clássica
qureg x[2]; // aloca um registrador quântico de dois bits na // máquina quântica
Mix(x); // força a superposição linear uniforme de // autoestados no registrador quântico x.
for i=1 to 5 { // o controle do laço é feito na máquina clássica
Not(x); // nega o conteúdo do registrador quântico x na // máquina quântica
}
measure x,d; // mede o valor na máquina quântica do registrador // x e envia o resultado a máquina clássica
// na máquina clássica, armazena o valor recebido em d.
return d; // retorna o valor da variável d da máquina clássica
No exemplo acima, observe que os comandos destinados a máquina clássica e a máquina quântica aparecem intercalados. A função Teste nega cinco vezes o conteúdo do registrador quântico x. Isso foi feito apenas para mostrar que o controle de laço é executado na máquina clássica enquanto que as operações quânticas são executadas na máquina quântica.
Quando o autor do presente texto começou a estudar QCL, não existia nem mesmo a operação lógica quântica AND. Como veremos mais adiante, a operação AND não é reversível e incrementa a entropia do sistema. Sendo assim, a operação quântica AND implementada pelo autor do presente texto difere ligeiramente da operação lógica AND de uma máquina clássica para permitir a reversibilidade e impedir o incremento da entropia. Diversos algoritmos que serão apresentados aqui foram implementados pelo autor do presente trabalho.
No presente tópico, serão estudados os aspectos mais básicos da linguagem QCL de interesse para a computação quântica. QCL possui diversos comandos existentes nas linguagens procedurais mais conhecidas; porém, deseja-se aprofundar a análise somente nos comandos úteis para a computação quântica. No presente tópico, serão estudados os comandos Mix, Not, CNot, qureg e measure. Será feito uso extensivo de exemplos para esclarecer a funcionalidade dos comandos aqui apresentados.
Para carregar o programa digitaremos a linha de comando como segue:
wind:~/qcl-0.4.0-bin$ qcl-static –bits=4
[0/4] 1 |0000>
qcl>
A opção -bits=4 especifica que queremos trabalhar com uma máquina que possui quatro qubits no total. A mensagem [0/4] significa que zero dos quatro qubits foram alocados. Ao lado, 1|0000> significa que o autoestado da máquina |0000> apresenta amplitude de probabilidade um. O prompt qcl> indica que já podemos entrar com novos comandos. No próximo passo, alocaremos um registrador quântico de dois qubits.
qcl> qureg x[2]
qcl> dump
: STATE: 2 / 4 qubits allocated, 2 / 4 qubits free
1 |0000>
O comando qureg x[2] aloca o registrador x com dois qubits.
O comando dump devolve o estado da máquina. Como pode ser observado
na saída do comando dump, 2 /
4 ou dois dos quatro qubits estão alocados e os outros 2 / 4 ou dois dos quatro
qubits estão livres. Por fim, vemos que a máquina continua no estado 1|0000>.
No próximo passo, começaremos a trabalhar com registradores quânticos:
qcl> Mix(x)
[2/4] 0.5 |0000> + 0.5 |0010> + 0.5 |0001> + 0.5 |0011>
Os dois qubits mais a direita de cada autoestado
correspondem aos dois qubits do registrador x. O comando Mix força
a superposição linear uniforme de autoestados no registrador que é passado como
argumento quando este está no estado em que todos os qubits estão em zero. Observe
que todos os autoestados apresentam 0.5 como amplitude de probabilidade. Lembrando
que a probabilidade de medição de um autoestado é o módulo quadrado de sua amplitude
de probabilidade, a probabilidade de cada um dos quatro autoestados é |0.5|2
= 0.25. No próximo passo, alocaremos mais um registrador.
qcl> qureg y[1]
qcl> dump
: STATE: 3 / 4 qubits allocated, 1 / 4 qubits free
0.5 |0000> + 0.5 |0010> + 0.5 |0001> + 0.5 |0011>
O comando qureg y[1] aloca o registrador quântico y com 1 qubit. O comando dump nos revela que três dos quatro bits quânticos estão alocados. Os dois qubits mais a direita de cada autoestado correspondem aos dois qubits do registrador x e o terceiro bit da direita para esquerda é o registrador y. No próximo passo, executaremos nossa primeira função lógica.
qcl> CNot(y,x)
[3/4] 0.5 |0000> + 0.5 |0010> + 0.5 |0001> + 0.5 |0111>
O comando CNot(y,x) nega os autoestados y correspondentes aos autoestados em que x possui seus bits todos em 1. O comando CNot é um comando de negação controlada. A semântica do comando CNot é baseada na semântica da porta lógica quântica proposta por Toffoli [BAR 95] chamada de Controlled Not ou simplesmente CNot. Observe que se podemos garantir que o registrador y começa em zero, CNot apresenta a mesma semântica da porta lógica AND em que y é a saída e x é a entrada. No exemplo anterior, observe que foram feitas quatro operações em paralelo. Para facilitar o entendimento, os bits referentes ao registrador y foram grafados em negrito. Se negarmos o resultado encontrado em y, teremos o resultado da operação x[0] NAND x[1] em y:
qcl> Not(y)
[3/4] 0.5 |0100> + 0.5 |0110> + 0.5 |0101> + 0.5 |0011>
Novamente, os bits referentes ao registrador y foram grafados em negrito. A importância do exemplo anterior deve-se ao fato de que qualquer função lógica pode ser descrita como uma composição de NANDs. No passo seguinte, declararemos uma variável inteira d e mediremos o estado de x. Vale lembrar que somente um autoestado sobrevive após a medição.
qcl> int d
qcl> measure x,d
[3/4] 1 |0011>
qcl> print d
: 3
O comando measure x,d mede x e carrega a variável d com o valor medido. O valor do autoestado de x que será medido depende da probabilidade de cada autoestado. Se x estiver em superposição linear uniforme de autoestados, cada autoestado tem a mesma probabilidade de ser encontrado. Sendo assim, poderemos encontrar 0,1,2 ou 3 com a mesma probabilidade. No exemplo anterior, o autoestado medido foi |11>; porém, qualquer outro autoestado de x poderia ter sido medido com a mesma probabilidade.
Considerando que a física envolvida na medição é não determinista, podemos construir uma função que gera zero ou um de forma aleatória.
int BitAleatorio() {
int d; // aloca uma variável inteira na máquina clássica.
qureg x[1]; // aloca um registrador quântico de um bit na máquina
// quântica.
Mix(x); // força a superposição linear uniforme de
// autoestados no registrador quântico x.
// x = c1|0> + c2|1> ; c1 = c2 .
measure x,d; // mede o valor na máquina quântica do registrador x e //envia o resultado à máquina clássica
// na máquina clássica, armazena o valor recebido em d.
return d; // retorna o valor da variável d da máquina clássica .
}
Foi estudado anteriormente como fazer a operação lógica NAND em QCL. No presente tópico, apenas para efeito de exemplo, será estudado como fazer a operação lógica XOR em QCL. Sendo assim, primeiramente, serão alocados os registradores quânticos:
qcl> qureg x[1]
qcl> qureg y[1]
qcl> qureg z[1]
Com os três comandos acima, foram alocados os registradores quânticos x,y e z com um qubit cada. No próximo passo, a superposição linear uniforme de autoestados para todas as combinações possíveis de x e y será forçada.
qcl> Mix(x&y)
[3/4] 0.5 |0000> + 0.5 |0010> + 0.5 |0001> + 0.5 |0011>
Cada autoestado acima tem a seguinte notação: |0zyx>. Conforme mostra a tabela que segue, o comando CNot será usado para copiar o conteúdo de x em z.
TABELA 2.1 – Usando o comando CNot para cópia.
|
X |
Y |
X e Y após CNot(X,Y) |
|---|---|---|
|
0 |
0 |
0 0 |
|
0 |
1 |
1 1 |
Para copiar o conteúdo de x em z, será usado o comando CNot(z,x):
qcl> CNot(z,x)
[3/4] 0.5 |0000> + 0.5 |0010> + 0.5 |0101> + 0.5 |0111>
Os bits referentes a z e x foram grifados em negrito. Supondo que x e y sejam registradores quânticos unários, a operação lógica CNot(x,y) é idêntica à operação x:= x xor y. Esta propriedade pode ser observada na tabela que segue.
TABELA 2.2 – Usando o CNot como operação XOR.
|
X |
Y |
X e Y após CNot(X,Y) |
X xor Y |
|---|---|---|---|
|
0 |
0 |
0 0 |
0 |
|
0 |
1 |
1 1 |
1 |
|
1 |
0 |
1 0 |
1 |
|
1 |
1 |
0 1 |
0 |
Sendo assim, o comando que segue concluirá o exemplo.
qcl> CNot(z,y)
[3/4] 0.5 |0000> + 0.5 |0110> + 0.5 |0101> + 0.5 |0011>
O conteúdo de z foi grifado em negrito. Pode-se verificar que z = x xor y.
Por si só, a operação lógica xor é um teste que retorna 1 quando seus operandos são diferentes. Sendo assim, a operação lógica xor é um teste de diferença. Para testar se dois operandos são iguais, faremos z = not ( x xor y ). Apenas por experiência, segue a seqüência de comandos QCL para encontrar z = not ( x xor y ):
qcl> qureg x[1]
qcl> qureg y[1]
qcl> qureg z[1]
qcl> Mix(x&y)
[3/4] 0.5 |0000> + 0.5 |0010> + 0.5 |0001> + 0.5 |0011>
qcl> CNot(z,x)
[3/4] 0.5 |0000> + 0.5 |0010> + 0.5 |0101> + 0.5 |0111>
qcl> CNot(z,y)
[3/4] 0.5 |0000> + 0.5 |0110> + 0.5 |0101> + 0.5 |0011>
qcl> Not(z)
[3/4] 0.5 |0100> + 0.5 |0010> + 0.5 |0001> + 0.5 |0111>
Por conveniência, o conteúdo de z foi grafado em negrito. Observe que z está no estado 1 quando x e y são iguais.
Pode-se observar que ausência de funções do tipo AND e OR dificulta a programação de funções lógicas em QCL. Por esse motivo, foi implementada a biblioteca boolean.qcl que possui as funções quAnd, quNand, quOr e quNor. Esta biblioteca é apresentada no Anexo 1.
No anexo 2, encontra-se uma implementação feita em QCL pelo autor do presente trabalho para resolver o problema np-completo SAT. Nessa implementação, as funções lógicas fazem uso da biblioteca boolean.qcl.
Quantos bits um único qubit pode representar? Em princípio, infinitos. O número de bits que um qubit representa depende do número de qubits e de que forma a que este qubit está relacionado. Supondo que os autoestados são representados na forma |0dee> em que d é o dado e ee é o endereço, aborda-se o seguinte exemplo:
qcl> dump
: STATE: 3 / 4 qubits allocated, 1 / 4 qubits free
0.5 |0000> + 0.5 |0110> + 0.5 |0001> + 0.5 |0111>
No exemplo acima, encontramos o dado 0 para os endereços 00 e 01 e o dado 1 para os endereços 10 e 11. No exemplo acima, representa-se 4 bits dispondo de 3 qubits. Supondo que dispõe-se de 9 qubits na forma |0deeeeeeee> em que d é o dado e eeeeeeee é o endereço, tem-se 8 qubits para o endereço resultando em 28 ou 256 endereços possíveis. Continuando o raciocínio, podemos representar 256 bits com apenas 9 qubits. Usando-se esse raciocínio, pode-se concluir que com n qubits podemos representar 2n-1 bits. Sendo assim, com 21 qubits pode-se representar 221-1 bits ou 1 megabit ou 128 kbytes.
Dado um registrador quântico em superposição linear de autoestados, como medir o autoestado desejado? No presente tópico, será apresentada uma técnica para incrementar o módulo da amplitude de probabilidade dos autoestados de maior interesse. Sendo assim, obteremos maior probabilidade de medir o autoestado desejado ao final da computação quântica. A técnica apresentada aqui é uma variação do algoritmo de Grover [GRO 96].
No diretório onde o simulador QCL é instalado, encontra-se o diretório lib. No diretório lib encontra-se o arquivo grover.qcl que possui a função diffuse. A função diffuse será usada juntamente com o comando CPhase para amplificar a amplitude de probabilidade do autoestado desejado.
Lembrando que a amplitude de probabilidade é um número complexo, ela pode ser descrita por um ponto no plano. O comando CPhase realiza uma rotação condicionada na amplitude de probabilidade possuindo dois parâmetros: a ângulo de rotação e o registrador que determina a condição. O comando CPhase rotaciona a amplitude de probabilidade para todo autoestado que apresenta o registrador que determina a condição com bits todos em 1. Segue o exemplo de uso do comando CPhase:
qcl1> include "grover.qcl"
qcl1> qureg x[3]
qcl1> Mix(x)
[3/6] 0.353553 |000000> + 0.353553 |000100> + 0.353553 |000010> +
0.353553 |000110> + 0.353553 |000001> + 0.353553 |000101> +
0.353553 |000011> + 0.353553 |000111>
qcl1> CPhase(pi,x)
[3/6] 0.353553 |000000> + 0.353553 |000100> + 0.353553 |000010> +
0.353553 |000110> + 0.353553 |000001> + 0.353553 |000101> +
0.353553 |000011>
+ -0.353553 |000111>
Observe que no exemplo acima a amplitude de probabilidade do autoestado |000111> sofreu rotação de 180 graus. Usando a função diffuse, amplifica-se a amplitude de probabilidade dos autoestados que apresentam amplitude de probabilidade negada.
qcl1> diffuse(x)
[3/6] -0.176777 |000000> + -0.176777 |000100> + -0.176777 |000010> +
-0.176777 |000110> + -0.176777 |000001> + -0.176777 |000101> +
-0.176777 |000011> + -0.883883 |000111>
No exemplo acima, observe que o módulo da amplitude de probabilidade
do autoestado |000111> sofreu um grande incremento.
A biologia tem sido fonte de inspiração para a inteligência artificial notadamente nas áreas de vida artificial, redes neurais e algoritmos evolutivos. A evolução da biologia é um processo de otimização natural dos seres vivos em que os melhor adaptados sobrevivem.
A forma como a vida processa informação em seu código genético é fonte de inspiração para novas formas de computação baseadas em processamento de moléculas de DNA. O estudo dos processos genéticos é útil para o estudo da computação biológica.
Primeiros milhões de anos após a formação da Terra: os relâmpagos e a luz ultravioleta do sol estavam decompondo as moléculas da atmosfera primitiva rica em hidrogênio. Novas moléculas de complexidade gradualmente maior combinavam-se na atmosfera. Os produtos da química atmosférica precipitavam-se no oceano que conseqüentemente se tornava quimicamente mais complexo [SAG 83].O Jardim do Éden molecular estava pronto. Caoticamente, a primeira molécula capaz de fazer cópias grosseiras de si mesma é formada. Toda uma estrutura de herança e evolução e toda atividade biológica que tivemos contato está baseada em uma molécula ancestral do ácido desoxirribonucléico, o DNA. Molécula principal da vida na Terra, o DNA tem a forma de uma escada em que cada degrau pode conter um de quatro tipos de nucleotídeos diferentes que são as quatro letras do alfabeto genético. Considerando que são necessários dois bits para representar uma de quatro alternativas possíveis ,cada letra do alfabeto genético carrega 2 bits de informação.
A vida é uma conseqüência da química orgânica. Na origem do universo e na origem da química, não foram definidas as regras da biologia. As regras da biologia emergem das regras da química. As regras do todo emergem das regras das partes. O comportamento do todo emerge do comportamento das partes. Considerando a química um sistema simples e a biologia um sistema complexo, o sistema complexo emerge do sistema simples. O aparecimento da vida é um exemplo de auto-organização.
No oceano primitivo não existiam predadores; existiam somente moléculas se duplicando. A evolução ao nível molecular seguia de forma implacável. Com o passar de milhões de anos, moléculas especializadas se agruparam formando as primeiras células primitivas [SAG 83].
A vida na Terra apareceu logo depois de sua formação. A Terra foi formada há 4.6 bilhões de anos atrás enquanto que a vida apareceu há 4 bilhões de anos. Considerando as dimensões de tempo, a vida apareceu pouco depois da formação da terra. Toda biologia da Terra possui código genético descrito na mesma cadeia de DNA com 4 nucleotídeos [SAG 83]. Seres humanos, árvores e bactérias são descritos pelo mesmo alfabeto genético. Darwin não poderia estar mais certo. O motivo pelo qual os organismos são diferentes está no fato de que suas instruções em seus códigos genéticos são diferentes ainda que seus alfabetos sejam os mesmos [SAG 77].
É interessante observar que o DNA é um sistema que armazena informação de forma digital. Por que a seleção natural escolheu um sistema de armazenamento de informação digital? Para efeito de cópia ou replicação, a informação digital é regenerada enquanto que a informação analógica é amplificada. Quando a informação analógica é replicada, os ruídos ou erros presentes na informação analógica são igualmente replicados ou até amplificados. De forma contrária, durante replicação, a informação digital pode ser regenerada e os ruídos podem ser filtrados. Sendo assim, a informação digital é mais resistente contra erros se queremos transportá-la através do espaço ou do tempo.
Os segredos da evolução são mutação, tempo, replicação e morte. A mutação é uma alteração de um nucleotídeo que é passado para a geração seguinte. A maior parte das mutações são desfavoráveis para o indivíduo enquanto que uma pequeníssima parte torna o indivíduo melhor adaptado melhorando suas chances de propagar seu DNA. A morte é responsável pela eliminação dos indivíduos menos adaptados contribuindo para a evolução. Considerando que o código genético é digital, a mutação também ocorre de forma digital.
Para Manfred Eigen [EIG 97], todo sistema que possua auto-replicação, mutação e metabolismo está sujeito a evolução. Sem a auto-replicação, a informação seria perdida a cada geração. Sem a mutação, a informação seria inalterável e não poderia emergir. Sem o metabolismo, o sistema cairia em equilíbrio significando a morte do ser vivo.
De forma mais abstrata, se queremos implementar um algoritmo de otimização, basta implementar a replicação e mutação de soluções e alguma pressão seletiva que selecione as soluções de maior interesse. A evolução é um processo de otimização. O ambiente em que o seres vivos habitam impõem uma pressão que seleciona os mais adaptados naturalmente. A pressão seletiva implicará na evolução das soluções.
Nenhum dos segredos da vida dependem de um determinado substrato. Algoritmos e heurísticas não dependem de substrato. Considerando que a vida é um processo algorítmico ou heurístico, então a vida não depende de substrato. Para que a vida evolua, basta que exista reprodução, mutação, morte e seleção ao longo do tempo e do espaço. Todos os segredos da vida estão espalhados pelo universo. Dentro de computadores podemos facilmente construir ambientes com os segredos da vida. É importante observar que a vida não depende de espaço e tempo contínuos tendo em vista que a continuidade não é necessária para a reprodução, morte e mutação.
Moléculas com funções especializadas formaram colônias que resultaram nas primeiras células. Há 3 bilhões de anos, os primeiros seres multicelulares evoluiram a partir de células vegetais. É importante observar que árvores e seres humanos são colônias de células. Cada célula também é uma colônia de seres vivos descendentes dos seres vivos que existiram no mar primitivo da Terra. O fato de que as mitocôndrias tenham seu próprio DNA sugere fortemente que elas sejam descendentes de organismos independentes do mar primitivo da Terra. Somos uma colônia de células em que cada célula também é uma colônia.
Há 2 bilhões de anos atrás, nas mesmas regras que ditam a evolução da vida, o sexo apareceu. O sexo é a troca de código genético entre organismos independentes. Com o sexo, segmentos de DNA podem ser trocados tornando o processo evolutivo tremendamente mais rápido. Antes do sexo, a única maneira de evoluir era por mutação. Os seres que podem trocar DNA tem a possibilidade de evoluir muito mais rápido do que aqueles que tem que esperar por uma mutação fortuita. Podemos afirmar que um dos segredos da evolução é o sexo. Não é por acaso que seres humanos apresentam grande interesse por troca de segmentos de código genético [SAG 77].
Há 1 bilhão de anos atrás, a atmosfera da Terra foi alterada de forma irreversível. Os vegetais da Terra fabricaram quantidades enormes de oxigênio molecular que foi lançado na atmosfera. As células vegetais possuem cloroplastos que são responsáveis por converter luz solar, água e dióxido de carbono em carboidratos e oxigênio. A atmosfera perdia suas características primitivas como a presença abundante de hidrogênio. O oxigênio, molécula altamente reativa com diversas moléculas orgânicas, foi um gás letal para a maior parte dos seres vivos desprotegidos [SAG 83].
Há 600 milhões de anos, o domínio das algas sobre o planeta foi perdido na revolução cambriana para uma enorme diversidade de novos e mais complexos seres vivos. Até então, a evolução ocorria principalmente no nível de estrutura celular e bioquímica. Pouco depois, apareceu o primeiro peixe e o primeiro vertebrado. Plantas migraram para a terra e a evolução seguiu seu curso [SAG 83]
Os organismos vivos mais simples
que conhecemos são os viróides que possuem menos de 10.000 átomos. Provavelmente
os viróides são descendentes de organismos mais complexos sendo dependentes
de organismos maiores para se reproduzir. Os organismos vivos de forma independente
mais simples que se tem conhecimento são conhecidos por PPLO que possuem cerca
de 50.000.000 de átomos [SAG 83].
Uma heurística não exige uma solução para cada entrada de seu domínio. Quando uma heurística encontra uma solução, não existe garantia de que a solução encontrada seja única ou ótima. Quando uma heurística não encontra uma solução, não existe garantia que a solução procurada não exista [JAM 84].
É interessante observar que o processo evolutivo que ocorreu e está ocorrendo em nosso planeta não garante que determinada espécie evoluirá a ponto de garantir a existência de seus descendentes. Processos algorítmicos garantem uma solução para cada entrada de seu domínio quando esta existe. Supondo que o problema de uma espécie seja evoluir e garantir a descendência, as leis que regem a seleção natural e o processo evolutivo planetário não oferecem garantia de solução para tal problema ainda que eventualmente possam levar a uma solução. Sendo assim, a evolução baseada na seleção natural é um processo heurístico. Vale observar ainda que espécies que sobrevivem à seleção natural não estão necessariamente em seu nível adaptativo ótimo.
Observando que o sexo apareceu somente há dois bilhões de anos atrás, concluímos que a evolução seguiu o seu curso durante mais de 2 bilhões de anos sem a existência de sexo. A evolução não depende do sexo. Antes do aparecimento do sexo, cada organismo vivo era descendente exclusivamente de seu indivíduo pai. Com o aparecimento do sexo, códigos genéticos de diferentes indivíduos carregando mutações que ocorreram em paralelo podem ser combinados para gerar um novo indivíduo. Sendo assim, enquanto que seres assexuados são resultado de mutações que ocorreram em série ao longo do tempo, seres sexuados são resultado de mutações que ocorreram em paralelo. O processamento em paralelo da informação genética determina uma maior velocidade evolucionária.
Vale lembrar que a evolução não depende do sexo. O sexo nasceu da evolução. A heurística da vida não depende do sexo. O sexo permite evolução em paralelo. A seleção natural preservou o processamento em paralelo do código genético.
Foi observado na seção 3.1.2 que para implementar um algoritmo evolutivo simples basta implementar reprodução, mutação e pressão seletiva. Na presente secção, será proposta uma forma de implementar um algoritmo evolutivo simples em uma máquina quântica.
Supondo a otimização da solução inicial |S>. Replicando-se e mutando-se cada um dos N filhos de |S> encontraremos a superposição que segue:
F = |S> + |S1> + |S2> + |S3> + ... + |SN>.
Basta um único registrador para armazenar todo o conjunto de filhos de |S>. Cada filho de |S> é um autoestado de F. A pressão seletiva pode ser simulada por uma função de avaliação que testa se |Sn> obedece a um critério de aptidão determinado. A medição sobre F provocará o colapso dos autoestados. Neste algoritmo, o colapso do vetor de autoestados é a morte de todas as soluções menos a sobrevivente.
O processo pode ser repetido indefinidamente. Ainda que simples, o algoritmo proposto é extremamente veloz tendo em vista que a função de avaliação será feita em paralelo.
A molécula de DNA é uma escada de nucleotídeos. Cada nucleotídeo é feito por 3 partes: uma base nitrogenada ( púrica ou pirimídica ), um açúcar e um ácido fosfórico [NOR 81]. O nucleotídeo leva o nome da base que é a parte que carrega informação. O DNA é uma longa seqüência do tipo ...-fosfato-açúcar-fosfato-açúcar-fosfato-... onde as bases estão ligadas nos açúcares da seqüência[FEL 88].
TABELA 3.1 - Bases encontradas no código genético
|
Bases Púricas |
Bases Pirimídicas |
|
Citosina (C) |
Adenina (A) |
|
Timina (T) |
Guanina (G) |
Usando a fórmula![]() em que p é a probabilidade do evento, podemos calcular
quantos bits cada nucleotídeo carrega. A probabilidade de que um determinado
nucleotídeo apareça é de ¼ ou 0.25. Sendo assim, cada nucleotídeo carrega
em que p é a probabilidade do evento, podemos calcular
quantos bits cada nucleotídeo carrega. A probabilidade de que um determinado
nucleotídeo apareça é de ¼ ou 0.25. Sendo assim, cada nucleotídeo carrega ![]() bits de informação. Vale observar
que os nucleotídeos são complementares. Adenina é complementar de Citosina e
Guanina é complementar de Timina.
bits de informação. Vale observar
que os nucleotídeos são complementares. Adenina é complementar de Citosina e
Guanina é complementar de Timina.
Um códon é definido por um conjunto de 3 nucleotídeos. Sendo assim, existem 4*4*4=64 códons diferentes. Cada códon corresponde a um tipo de aminoácido diferente. O problema é que existem somente 20 tipos de aminoácidos, tornando o código redundante. Existem diferentes códons para o mesmo aminoácido permitindo que uma mutação transforme um códon em um códon equivalente ou sinônimo sendo esta uma mutação neutra. Na década de 50, incorretamente foram feitas propostas de modelos genéticos em que códons mais comuns poderiam usar menos nucleotídeos bem ao estilo do código de compressão de Huffman. A idéia geral do código de compressão de Huffman é representar com menos bits os eventos mais freqüentes e representar com mais bits os eventos menos freqüentes. A redundância existente no código genético permite alguma proteção contra mutações. Em simulações feitas por computador, David Haig e Laurence D. Hurst mostraram que o código redundante do DNA está quase no nível ótimo no que tange à proteção a mutações [HAY 98].
Considerando que o DNA humano possui cerca de 5 bilhões de nucleotídeos
[SAG 77] e que cada códon é composto de 3 nucleotídeos,
podemos concluir que o DNA humano possui cerca de 1.7 bilhões de códons. Para
facilitar o cálculo, supomos que os códons referentes aos 20 aminoácidos sejam
equiprováveis. Sendo assim, o número de bits necessário para representar o DNA
humano será de![]() bits ou 918 megabytes! A quantidade de DNAs
diferentes de tamanho de
bits ou 918 megabytes! A quantidade de DNAs
diferentes de tamanho de ![]() bits é de exatos
bits é de exatos ![]() .
.
Toda vida que conhecemos e subseqüentemente toda inteligência biológica que conhecemos está baseada em DNA. Entender o funcionamento, o protocolo e as regras em que o DNA é escrito e interpretado são essenciais no entendimento da vida. Se queremos falar de vida e inteligência artificial deveremos falar sobre a computacionalidade do DNA. No presente tópico, pretende-se examinar aspectos que possam ser importantes sobre o código genético para cientistas da computação.
Em um computador, um programa é um conjunto de dados e instruções que operam sobre esses dados. Vale observar que o próprio programa é uma informação contida na memória do computador. Podemos olhar o DNA como uma memória que possui dados e instruções analogamente à memória de um computador.
Ainda que as regras básicas de formação do DNA de uma árvore, bactéria ou um primata sejam semelhantes, a semântica ou significado associado a certos códons ou genes pode variar. Na genética bacteriana, existem conjuntos de genes que são ativados em conjunto por um único operador. A ativação de um gene resulta na fabricação de um composto de aminoácidos. Quando um operador é ativado, todo o seu conjunto de genes é ativado. A ativação de um operador lembra a chamada de função que resulta na execução das instruções que descrevem a respectiva função. O operador pode ser ativado ou suprimido por um outro gene chamado de regulador situado em outro lugar do genoma.
O gene é composto por uma seqüência de códons. Considerando que cada códon corresponde a um aminoácido, cada gene corresponde a um composto de aminoácidos. O gene regulador exerce função de controle. O gene regulador controla a ativação ou supressão do gene operador. Quando um gene operador é ativado, ele desencadeia a ativação de todo o conjunto de genes a que pertence.
Abordando um exemplo, vamos supor um gene regulador que comanda um gene operador que ativa a produção de enzimas que metabolizam um açúcar. Apenas haverá sentido disparar a produção dessas enzimas quando existir a presença de açúcares. O gene regulador deverá reagir à presença do açúcar ativando o gene operador que é responsável pela produção de enzimas que metabolizarão o açúcar e deverá desativar o gene operador na falta de açúcares. É interessante observar que um gene somente pode estar em dois estados lógicos mutuamente exclusivos que são “ativado” e “desativado”.
O DNA não é o único lugar onde existe informação. O estado bioquímico de uma bactéria pode ser um tipo de memória sobre a qual os reguladores fazem seus testes. No exemplo do açúcar, os estados de memória em relação ao açúcar poderiam ser hipoglicêmico, normal ou hiperglicêmico.
Podemos olhar uma bactéria como um hardware em que a informação do seu DNA é o seu software. Ao olhar a tabela apresentada acima, fica evidente a semelhança entre funções biológicas que encontramos em bactérias e funções que encontramos em computadores.
Quando trabalha-se com textos em computadores, é comum trabalhar com longas seqüências de caracteres em código ASCII. Cada letra do alfabeto possui um correspondente no código ASCII. Para o fim de linha, comumente usamos um caractere terminador de índice 13 (0DH ou ENTER ou CR). Abordando a comparação do DNA com uma longa seqüência de caracteres, assim como nas seqüências ASCII, também existe um símbolo terminador no DNA que pode ser um dos códons UAA, UAG ou UGA em bactérias. Existem indicações de que UAA é um códon de terminação no homem [NOR 81].
Em uma seqüência de caracteres longa, a supressão de um único bit ou de um conjunto de bits não múltiplos de 8 (bytes) acarreta um descompasso de sua leitura tornando-a ininteligível perdendo até os símbolos terminadores. Da mesma forma, a perda de um nucleotídeo ou um conjunto de nucleotídeos não múltiplos de 3 acarreta na perda de longas seqüências de código incluindo os terminadores.
Quando um computador está pr'ocurando por vírus em sua memória, ele varre toda a memória procurando por uma seqüência definida de bytes que identifique a presença de um determinado tipo de vírus na máquina. Em uma bactéria, a situação é extremamente semelhante. Quando uma bactéria é invadida por um DNA estranho ( de origem viral ), o DNA estranho poderá ser interceptado por uma enzima de restrição que varrerá o DNA até encontrar uma seqüência de códons previamente definida. Em caso afirmativo, o DNA será quebrado. Por exemplo, sempre que a enzima Eco R1 encontra uma seqüência do tipo GAATC, o DNA será quebrado [NOR 81].
TABELA 3.2 - Enzimas de restrição e DNAs virais
|
Enzimas de Restrição |
Seqüência de DNA supostamente viral |
|---|---|
|
Eco R1 |
GAATC |
|
Hind III |
AAGCTT |
|
Hinf I |
GANTC |
|
Hpa I |
GTTAAC |
Considerando que as enzimas são processadores de moléculas, já que podem quebrar e compor moléculas, se as moléculas que uma enzima processa possuem informação, a enzima está processando não apenas moléculas que carregam informação como está processando a própria informação.
No tópico anterior, foi observado que enzimas podem processar informação. No presente capítulo, será estudada a proposta de Leonard Adleman [ADL 94][ADL 96] para a construção de um computador molecular. Adleman é professor atuante nos departamentos de ciência de computação e de biologia molecular da University of Southern California [ADL 2000].
A idéia básica do computador molecular é: cada molécula mergulhada em um tubo de ensaio pode ser uma unidade de processamento de informação. Sendo assim, um tubo de ensaio contendo as moléculas certas é um sistema de processamento de informação massivamente paralelo.
No presente tópico, será estudado um modelo abstrato de computação molecular. Esse modelo foi desenvolvido baseando-se nas propriedades químicas do DNA. Nesse modelo, um tubo de ensaio contém moléculas de DNA representadas por palavras no alfabeto {A,C,G,T}. As operações permitidas sobre um tubo de ensaio são as que seguem:
Separação ou Extração: dado um tubo de ensaio contendo palavras do alfabeto {A,C,G,T}, a operação +(T,s) separa todas as palavras que contenham a seqüência s enquanto que -(T,s) separa todas as palavras que não contenham a seqüência s.
Exemplo:
T1 = { ACGT , ACCT , ATCG, ATCC }
Operando-se T2 = +(T1,CG) e T3 = -(T1,GC) encontra-se:
T2 = { ACGT , ATCG } e T3 = { ACCT , ATCC }
Mescla: dados os tubos T1 e T2, U(T1,T2) = T1 U T2.
Exemplo:
T2 = { ACGT , ATCG } e T3 = { ACCT , ATCC }
T4 = U(T2,T3) = { ACGT , ACCT , ATCG, ATCC }
Detecção: dado um tubo de ensaio T, responde “sim” se existe no tubo ao menos uma molécula de DNA e responde “não” se não existe nenhuma molécula de DNA no tubo.
Exemplo:
T1 = { ACGT , ATCG } e T2 = {}
Detect(T1) = “sim” e Detect(T2) = “não”
Amplificação: dado um tubo T1, a amplificação gera outros dois tubos T2 e T3 idênticos a T1. A notação é a que segue: T1 = T2(T1) = T3(T1).
Com as quatro operações apresentadas anteriormente, podemos escrever programas de computação molecular. A seguir, será apresentado um programa bastante simples:
Imput(T)
T1 = - (T,G)
Detect (T1)
O programa apresentado testa se no
tubo T existe alguma molécula que não contenha o símbolo G. O próximo programa
será ligeiramente mais complexo:
Imput(T)
T1 = - (T,G)
T2 = - (T1,C)
T3 = - (T2,T)
Detect (T3)
O programa listado acima testa se existem moléculas formadas exclusivamente de símbolos A.
Devem ser feitas considerações sobre o fato de que não é simples construir um computador molecular com a operação de amplificação. A operação de amplificação consome matéria e exige ligações químicas covalentes o que dificulta o processo.
No presente capítulo, foi abordado um modelo de computação molecular baseado em moléculas de DNA; porém, é possível usar outros tipos de moléculas mantendo as mesmas abstrações apresentadas até aqui.
Apesar das restrições apresentadas, no próximo tópico, resolveremos um problema np-completo: testar se um grafo é colorível com apenas 3 cores de forma que dois vértices ligados por arestas não apresentem a mesma cor. Se o leitor não souber o que é um problema np-completo, recomenda-se a leitura do anexo 1.
A aplicação a ser abordada no presente tópico é testar se dado um grafo é possível colorir os vértices com apenas três cores de tal forma que dois vértices ligados por uma aresta não apresentem a mesma cor.
Dado um grafo G de arestas A1, A2 ,.., Az, seja:
n é o número de vértices;
z é o número de arestas;
S = {r1, g1, b1,r2, g2, b2, ..., rn, gn, bn} ;
a entrada do programa T em que
T = { ![]() |
|![]() &
& ![]() = { c1, c2, ...,
cn} & [ci = ri ou ci = bi
ou ci = gi], i = 1,2, ..., n }
= { c1, c2, ...,
cn} & [ci = ri ou ci = bi
ou ci = gi], i = 1,2, ..., n }
Apenas para efeito de exemplo, a palavra r1b2g3 representa a situação em que o vértice 1 é vermelho (r), o vértice 2 é azul (b) e o vértice 3 é verde (g). A entrada T contém todas as possíveis colorações para o grafo.
Seja o programa:
Input(T)
for k = 1 to z. Let Ak = <i,j>:
Tred = +(T,ri) and Tblue or green = -(T,ri)
Tblue = +(Tblue or green,bi) and Tgreen = -(Tblue or green,bi)
Tgood red = -(Tred,rj)
Tgood blue = -(Tblue ,bi)
Tgood green = -(Tgreen ,gi)
T1 = U(Tgood red, Tgood blue )
T = U(T1, Tgood green )
Output(Detect(T))
De forma simples, apenas para efeito de entendimento, o mesmo algoritmo poderia ser simplificado à forma que segue:
Input(T)
for k = 1 to z. Let Ak = <i,j>:
Descarta entrada de T quando a cor
do vértice i é igual a cor do vértice j.
Output(Detect(T))
Considerando o primeiro passo em que k=1, A1 é a aresta que liga os vértices i e j. O tubo green receberá todos grafos que possuem o vértice i verde; o tubo red receberá todos os grafos que possuem o vértice i vermelho; o tubo blue receberá todos os grafos que possuem o vértice i azul.
O tubo Tgood red receberá todos os grafos em que o vértice i é vermelho e o vértice j não. O tubo Tgood blue receberá todos os grafos em que o vértice i é azul e o vértice j não. O tubo Tgood green receberá todos os grafos em que o vértice i é verde e o vértice j não.
Por fim, o tubo T receberá a união dos tubos Tgood red , Tgood blue e Tgood green. Todo o processo descrito será repetido para k no intervalo de 1 até z.
Ao final da execução do programa, as moléculas existentes ao tubo T correspondem as maneiras possíveis de colorir o grafo. Sendo assim, se existir pelo menos uma molécula no tubo T, então o grafo é 3-colorível.
Durante sua execução, o programa apresentado despende 5k separações, 2k uniões e um teste. O programa apresentado resolve um problema NP-completo em tempo linear devido ao poder do processamento de informação massivamente paralelo proporcionado pela computação molecular.
Cada molécula em um tubo de ensaio ocupa um determinado espaço. O paralelismo da computação molecular vem da enorme quantidade de moléculas que podem ser colocadas em um único tubo de ensaio. O paralelismo das máquinas moleculares depende do número de moléculas envolvidas. Se o número de moléculas com que podemos trabalhar é determinado pelo tamanho do tubo de ensaio e pelo tamanho de cada molécula, então obteremos um maior número de moléculas se de alguma maneira pudermos trabalhar com tubos de ensaio maiores ou com moléculas menores. No presente capítulo, foram estudadas maneiras de realizar computação molecular com DNA.
Em princípio, não existe razão pela qual não seja possível realizar computação molecular com moléculas inorgânicas. O uso do DNA deve-se ao fato de termos muita pesquisa e desenvolvimento tecnológico prontos em DNA. Não existe motivo para não considerar a possibilidade que em algum ponto do futuro as moléculas de DNA sejam substituídas por moléculas menores ou com propriedades interessantes quaisquer para a computação.
Provavelmente, muitos biólogos não tinham a menor idéia de que suas pesquisas seriam fonte de inspiração para engenheiros e cientistas de computação. Da mesma forma, especula-se que muitos dos resultados do desenvolvimento da computação molecular e biológica terão mais importância para a medicina e biologia do que para a ciência da computação.
Cientistas de computação gostam de trabalhar no domínio da informação.
Na computação molecular, o resultado de uma computação é um conjunto de moléculas.
Cientistas de computação verão no resultado da computação um punhado de informação.
Por outro lado, para o mesmo resultado, biólogos ou médicos poderão ver nas
mesmas moléculas resultantes a cura para alguma doença.
Deste o aparecimento da vida na Terra e durante toda sua evolução, a vida explorou os recursos materiais e leis físicas existentes para evoluir. Durante a evolução, a vida não tem consciência de que caminho evolutivo está tomando: as mutações ocorrem fortuitamente e os mais aptos sobrevivem. Sendo assim, se de alguma forma a vida pôde aproveitar as leis da física quântica durante quatro bilhões de anos de evolução, é provável que a física quântica participe de algum processo biológico.
No ítem entitulado Computação Evolutiva e Evolução Biológica, atenta-se para o fato de que o DNA é um sistema de informação digital de base 4. A experiência humana em construir computadores digitais mostra que é muito mais fácil construir dispositivos lógicos binários ( base dois ) do que construir dispositivos lógicos em bases maiores. Por que a vida escolheu um sistema digital em base 4? No artigo Quantum Algorithms and the Genetic Code, Apoorva Patel [PAT 2000] sugere que a resposta pode estar no algoritmo quântico de pesquisa em banco de dados desordenado proposto por Lov Grover [GRO 96] [BOY 98]. O único algoritmo clássico para pesquisa em banco de dados desordenado é varredura.
Para Patel [PAT 2000], a tarefa computacional envolvida na replicação do DNA é montagem. Os blocos de construção já existem e estão flutuando no ambiente onde o DNA está inserido. Dada uma cadeia simples de DNA, ao replicar-se, as bases (A,C,G,T) tem que ser retiradas uma a uma do ambiente e montadas. Esse processo assemelha-se ao processo de busca em banco de dados desordenado.
Voltando a computação quântica, para o caso especial em que o estado de um registrador quântico é a superposição linear de 4 autoestados, a pesquisa nesse vetor de autoestados é determinista e sempre retorna valores corretos. Patel [PAT 2000] sugere que a montagem do DNA durante a replicação é uma implementação natural da pesquisa quântica em um vetor de 4 autoestados.
Em 1997, o matemático Lov Grover da divisão de pesquisa da IBM mostrou que um computador quântico pode fazer consultas em banco de dados muito mais rápido do que qualquer dispositivo clássico. Começando com superposição linear de autoestados em que cada autoestado é uma entrada do banco de dados, a pesquisa resume-se a amplificar o autoestado desejado [BUC 2000].
Por coincidência Patel e Grover foram colegas de graduação na Caltech no início dos anos 80. Os cálculos de Grover respondem de forma exata que o número de tentativas quânticas para encontrar 1 elemento de 4 possíveis é 1. Em outras palavras, basta uma tentativa quântica para reconhecer uma dentro de 4 possibilidades [BUC 2000]. Para Patel [PAT 2000], o aspecto computacional da replicação do DNA é escolher uma de 4 bases possíveis e montar.
Será apresentada aqui uma variação do algoritmo de Grover [GRO 96] para simular a superposição linear e busca das bases A,C,G e T. Os pares possíveis são: AT, CG, TA e GC. Na presente modelagem, cada base e cada par correspondem a um autoestado de acordo com a tabelas 4.1 e 4.2.
TABELA 4.1 – Bases e autoestados correspondentes
|
Base |
Autoestado Correspondente |
|---|---|
|
A |
|A> ou |00> ou |0> |
|
T |
|T> ou |11> ou |3> |
|
C |
|C> ou |01> ou |1> |
|
G |
|G> ou |10> ou |2> |
TABELA 4.2 – Pares e autoestados correspondentes
|
Par |
Autoestado Correspondente |
|---|---|
|
AT |
|AT> ou |0011> |
|
TA |
|TA> ou |1100> |
|
CG |
|CG> ou |0110> |
|
GC |
|GC> ou |1001> |
Nos próximos parágrafos, será feita uma simulação para encontrar a base que forma par com a base G (|G> ou |10> ou |2>).
As instruções que seguem farão com que os registradores x e y correlacionados representem todos os pares possíveis:
qcl1> qureg x[2]; qureg y[2]; Mix(x);
[4/4] 0.5 |0000> + 0.5 |0010> + 0.5 |0001> + 0.5 |0011>
qcl1> quXor(y,x); Not(y)
[4/4] 0.5 |1100> + 0.5 |0110> + 0.5 |1001> + 0.5 |0011>
Tendo-se todos os pares possíveis em superposição uniforme de autoestados, usa-se a técnica apresentada na seção 2.3.8 para amplificar apenas a solução desejada. Na próxima instrução, a amplitude de probabilidade do autoestado em que y=|G> será negada.
qcl1> quPICPhase(y,2);
[4/4] 0.5 |1100> + 0.5 |0110> + -0.5 |1001> + 0.5 |0011>
Agora, basta amplificar a resposta desejada. O ponto de exclamação indica que deve ser executada a computação reversa. Por exemplo, !quXor(x,y) indica que deve ser executada a computação reversa de quXor(x,y).
qcl1> !Not(y); !quXor(y,x)
[4/4] 0.5 |0000> + 0.5 |0010> + -0.5 |0001> + 0.5 |0011>
qcl1> diffuse(x)
[4/4] -1 |0001>
qcl1> print x
1 |01>
Encontramos a resposta esperada com 100% de certeza. A resposta 1 |01>significa que deterministicamente a solução é C. A solução está correta tendo em vista que é verdade que G pareia-se com C. Este é um caso raro onde a medição é determinista.
A física quântica não é novidade na biologia. Quando um fóton é absorvido por uma célula fotossintetizante, a sua energia excita um elétron deslocalizado ao longo de dezenas de moléculas. A proposta de Patel é ainda mais radical, a proposta de Patel envolve superposição quântica das bases sendo moléculas inteiras. Quanto mais massivo é um objeto, menos óbvias são suas propriedades quânticas [BUC 2000].
Em entrevista à revista New Scientist, Grover afirma [BUC 2000] :
“Apoorva [Patel] gera uma porção de idéias ... depois de tudo, por que a evolução não exploraria qualquer avenida quântica aberta?”
Nos capítulos anteriores, despendemos enorme esforço para estudar física e computação quântica. No presente capítulo, usaremos os conhecimentos recém adqüiridos para entender as argumentações de que a inteligência é ou não resultado de processos quânticos sobre a informação.
Para cada opinião apresentada sobre a física do cérebro, ao final, serão apresentados comentários feitos pelo autor do presente texto.
Entender a física do cérebro é extremamente importante para a inteligência artificial. Conforme veremos adiante, constataremos que a forma como o cérebro é modelado torna impraticável um ou outro tipo de implementação artificial.
Stapp [STA 95] propõe uma questão interessantíssima: “como pode a unicidade da consciência emergir de uma coletividade de neurônios?”. Nós normalmente nos consideramos e sentimos indivíduos e não colônias de células. A nossa consciência nos reconhece como unidades e não como fruto de coletividade. Por outro lado, sabemos que o processamento no cérebro é massivamente paralelo. No cérebro, enormes quantidades de neurônios processam informação em paralelo enquanto nos afirmamos conscientes como unidades. Stapp pergunta: “ Como atividades neurais em diferentes regiões do cérebro podem ser componentes de uma única entidade psicológica?”
No entendimento de Stapp, o fundamento principal da mecânica clássica é que qualquer sistema físico pode ser decomposto em uma coleção de elementos simples e locais que interagem somente com seus vizinhos. Se o cérebro obedece a mecânica clássica, então ele pode ser decomposto em partes físicas e ser entendido através de suas partes. Sendo assim, o cérebro pode ser simulado em um computador massivamente paralelo.
Stapp propõem uma definição para descrição intrínseca: “a descrição básica ou intrínseca de um sistema é a descrição de o que o sistema é ( de acordo com a física clássica ) nos termos de seus componentes independentes.”
As imagens formadas nos monitores de vídeo de computadores digitais podem ser descritas por uma matriz de pontos que brilham. A descrição intrínseca da imagem que observamos na tela do computador é simplesmente a cor e a intensidade de cada ponto que observamos.
A descrição extrínseca é a descrição que pode ser formada na mente de um observador externo que tem a habilidade de perceber toda a coleção de números que formam a descrição intrínseca como um todo. A descrição extrínseca da imagem que é vista em uma tela de computador pode ser algo como: “um triângulo”.
Uma coleção completa de entidades logicamente independentes que constituem uma descrição intrínseca pode ser representada por uma única entidade básica de descrição extrínseca. Em geral, coleções de entidades independentes de nível intrínseco podem ser representadas como entidades individuais de nível extrínseco.
No entendimento de Stapp, na física clássica, para simular o cérebro, basta que para cada unidade de processamento cerebral exista uma unidade de processamento computacional que o simule. Considerando o cérebro um sistema físico, quanto mais simples e menores forem definidas as unidades de processamento do cérebro (subsistemas físicos), menor será a complexidade necessária para definir cada uma dessas unidades de processamento.
Na física clássica, o estado e a dinâmica de um sistema físico são descritos intrinsecamente. A descrição dos pensamentos de uma pessoa é uma descrição extrínseca enquanto que a descrição do cérebro é uma descrição intrínseca.
O questão proposta no início continua não respondida: como pode surgir a unicidade da consciência se ela é fruto de funções cerebrais que ocorrem em paralelo? Na física clássica, é possível dividir um sistema físico em partes individuais e logicamente separadas; porém, nem todo sistema físico quântico pode ser separarado em partes isoladas. Partículas quânticas podem estar correlacionadas mesmo que separadas por vários anos luz. De certa forma, uma partícula não tem um estado próprio, ela tem um estado que depende das outras partículas a que está correlacionada. Vale lembrar que o colapso do vetor de estados ocorre sobre todas as partículas correlacionadas ao mesmo tempo mesmo que elas estejam separadas por vários anos luz. No entendimento de Stapp, todo sistema físico é um sistema quântico na medida em que todo sistema físico é composto de partículas que obedecem a física quântica. Sendo assim, nem todo sistema físico pode ser modelado de forma intrínseca ou através de suas partes.
Na física quântica, um sistema físico não é simplesmente a soma de seus subsistemas: partículas quânticas correlacionadas apresentam um estado que somente pode ser descrito em conjunto. Não podemos descrever intrinsecamente o estado de um elétron correlacionado a outros elétrons.
Para Stapp, a resposta da unicidade da consciência está na unicidade do sistema físico quântico.
O trabalho de Stapp vale pela pergunta:
“ How can neural activities in different locations in the brain be components of a single psychological entity?”
Independentemente da resposta de Stapp estar certa ou errada, o simples fato de a pergunta ter sido feita e divulgada e posta a crítica da comunidade científica já é motivo para acreditar que a pergunta de Stapp é um avanço para a ciência.
Se a física quântica é importante na descrição do sistema físico chamado cérebro, então será muito difícil simular tal sistema em uma máquina clássica. Devemos lembrar que um sistema físico de N elétrons correlacionados exige 2N bits para representação apenas dos seus spins. Sendo assim, se Stapp estiver correto, para construir consciências artificiais, será necessário construir máquinas quânticas.
Klein [KLE 95] questiona: a ciência clássica ( não quântica ) é incapaz de entender o funcionamento do cérebro? Os efeitos quânticos de longo alcance são suficientes para produzir variações perceptíveis na atividade neural? As respostas de Klein serão apresentadas nos próximos parágrafos.
Supondo-se um neurônio que está em superposição linear de autoestados A ( o neurônio dispara) e B ( o neurônio não dispara). Tal superposição de autoestados pode ser descrita como a|A> + b|B>. Klein acredita que a diferença de energia envolvida em um neurônio que dispara ou não dispara é muito grande para se manter em superposição linear. Sendo assim, qualquer superposição linear de autoestados perceptível deve ocorrer antes do disparo ou não do neurônio.
Klein argumenta que será difícil encontrar efeitos quânticos na atividade neural antes do disparo. O grande problema em relação a superposição linear no cérebro é que o cérebro trabalha a altas temperaturas ( existem vibrações termais constantes das proteínas e outras moléculas envolvidas na atividade neural ). É extremamente provável que os autoestados |A> e |B> se correlacionem com o ambiente. Quando isso ocorre, os desvios de comportamento em relação a física clássica são mínimos. Ainda que os microtubos possam manter coerência quântica no seu interior, não existe forma de manter coerência quântica entre neurônios.
Klein argumenta que não necessitamos de física quântica para descrever o funcionamento do cérebro. Essa opinião é contrária a opinião de Stapp. Klein é muito convincente em sua argumentação que não existe maneira conhecida de manter correlação quântica entre neurônios por ser o cérebro um ambiente muito quente. Se Klein estiver correto, poderemos construir o computador cérebro de Stapp apenas com dispositivos clássicos.
Por hipótese, se para cada sistema físico concebível existe uma máquina de Turing que o simule, então uma bactéria, um cérebro ou o universo podem ser simulados em uma máquina de Turing. No entendimento de Dorit Aharonov [AHA 98], para cada sistema físico parece existir uma máquina de Turing que o simule. Stephen Wolfram [REG 87] questiona se o universo é um autômato celular gigante. Se o universo é um autômato celular gigante, certamente existe uma máquina de Turing que simula o universo. Para Edward Fredkin [HAM 87], não existe dúvida: o universo é um grande autômato celular. Klaus Haefner [HAE 92] apresenta a hipótese de que todo sistema composto de matéria e energia é um sistema de processamento de informação. Possivelmente, o processamento de informação nasce com o nascimento do universo e da física. Assim como regras lógicas descrevem o processo sobre a informação, a física é a regra que rege o universo. Sendo assim, o processamento de informação não nasceu nem com a vida e nem com o cérebro. O processamento de informação está espalhado pelo espaço e tempo em todo universo.
Roger Penrose afirma [PEN 94]: “appropriate physical action of the brain evokes awareness, but this physical action cannot even be properly simulated computationally”. Se para todo sistema físico existe uma máquina de Turing que o simule e se o cérebro é um sistema físico, então existe uma máquina de Turing que simula o cérebro e Penrose está errado.
Supondo que a máquina de Turing é uma máquina que processa informação e que para todo sistema físico existe uma máquina de Turing equivalente, podemos concluir que todo sistema físico é um sistema que processa informação. Essa conclusão é muito semelhante a hipótese de Klaus Haefner [HAE 92].
Alguns físicos se perguntam se os nossos formalismos lógicos e matemáticos são suficientes para representar toda a realidade física. Supondo que formalismos lógicos e matemáticos não são suficientes para representar toda realidade física e que computadores são projetados sobre formalismos lógicos e matemáticos, então os computadores apresentam uma capacidade de computação aquém da capacidade permitida pela física [WIL 97]. Novamente, devemos pensar em computadores como algo que existe fisicamente. A computação depende do que pode ser fisicamente computado. O estudo da física é extremamente importante para entendermos o que pode e de que maneira ser físicamente computado. Aparentemente, todo sistema físico pode ser simulado por uma máquina de Turing[AHA 98].
Considerando que todo sistema físico
pode ser simulado por uma máquina de Turing e que toda máquina é um sistema
físico, não poderemos construir máquinas mais poderosas que a máquina de Turing.
Fazendo uso da tecnologia quântica e da tecnologia biológica, poderemos construir
máquinas que resolvem problemas computáveis de forma extremamente rápida; porém,
pelos motivos já apresentados, não poderemos construir máquinas de maior poder
computacional do que a máquina de Turing.
Ao longo do presente trabalho, estudou-se novas formas de computação baseadas em física quântica e química orgânica. Conforme pode ser observado, a forma de escrever programas para computadores quânticos ou moleculares é diferente da forma de escrever programas para computadores clássicos.
No capítulo 2, mostrou-se que o estado de uma partícula quântica é descrito pela superposição linear de autoestados. Uma única partícula pode ser usada para representar grandes quantidades de informação sendo que o processamento sobre essa partícula processa a informação que ela representa de forma paralela.
Ainda no capítulo 2, apresentou-se a linguagem QCL que permite a construção de programas para computadores quânticos de forma simples. Ainda que a maneira de programar um computador quântico seja bem diferente da maneira de programar um computador clássico, no entendimento do autor do presente trabalho, programadores que já programam computadores clássicas aprenderão a programar computadores quânticos despendendo poucos meses de estudo.
Espera-se que presente trabalho popularize a computação quântica entre programadores de língua portuguesa. Com sorte, o presente trabalho servirá como fonte de inspiração para futuros programadores de computadores quânticos.
No capítulo 3, estudou-se fundamentos de genética e mostrou-se alguns aspectos onde a vida usa a química orgânica como meio para processar informação. Ainda no capítulo 3, mostrou-se que a mesma química que a vida usa para processar informação pode ser usada artificialmente para a construção de computadores.
No capítulo 4, estudou-se a proposta de Patel que sugere que o processo químico de montagem de seqüências de DNA é semelhante ao algoritmo de pesquisa quântica em banco de dados desordenado. Ainda no capítulo 4, estudou-se as idéias de Stapp e Klein sobre a importância da computação quântica nos processos que ocorrem no cérebro. Aparentemente, a física quântica não apresenta papel efetivo no disparo ou não dos neurônios.
Podem ser observadas diversas semelhanças na forma de programar uma máquina quântica e uma máquina biológica. Na seção 3.2.2, foi apresentado um algoritmo para coloração de grafos. A idéia principal do algoritmo é avaliar todas as formas possíveis de colorir os vértices do grafo selecionando aquelas que obedecem ao critério 3-colorível.
Considerando as semelhanças na maneira de projetar software na computação quântica e na computação molecular, o autor do presente trabalho propõe uma forma de implementar o algoritmo da seção 3.2.2 em uma máquina quântica.
Antes de implementar o algoritmo propriamente dito, devemos escolher uma maneira
de representar os dados. Tem-se três cores para representar. Cada cor será representada
por um autoestado de dois bits de acordo com a tabela que segue:
TABELA 5.1 – Cores e autoestados correspondentes
|
Cor |
Autoestado |
|---|---|
|
r |
|00> |
|
g |
|01> |
|
b |
|10> |
O registrador quântico T representa as cores dos vértices. A cor de cada vértice é representada por dois bits sendo que a cor do vértice i é representada por T[i*2] & T[i*2+1]. Supondo que |00100001> é autoestado de T, então esse autoestado representa um grafo em que o vértice 1 tem cor |10>; o vértice 2, cor |00> e o vértice 3, cor |01>. Os primeiros dois bits do autoestado não são usados.
O registrador ArestaInvalida é um vetor de qubits em que cada elemento de índice k-1 recebe o valor 1 quando a aresta de índice k liga vértices de mesma cor.
O algoritmo para decidir se um grafo é 3-colorivel em máquina quântica pode ser implementado como segue:
qureg T[n*2+2]; //n é o número de vértices;
qureg CorInvalida[n+1]; //z é o número de arestas;
qureg ArestaInvalida[z];
qureg GrafoInvalido[1];
Mix(T);
int k;
for k = 1 to z { // elimina as cores |11>
CNot(CorInvalida[k],T[K*2] & T[K*2+1]);
CNot(T[K*2],CorInvalida[k]);
CNot(T[K*2+1],CorInvalida[k]); }
for k = 1 to z {
Let Ak = <i,j>;
// Compara se as cores dos vertices i e j são iguais.
quEqual(ArestaInvalida[k-1],T[i*2] & T[i*2+1],T[j*2] & T[j*2+1]);}
quVectOr(GrafoInvalido[0], ArestaInvalida);
As linhas 14 e 15 chamam funções quânticas presentes na biblioteca boolean.qcl. O comando da linha 12 não pertence a linguagem QCL.
No algoritmo acima apresentado, o registrador quântico GrafoInvalido apresenta valor 1 quando o grafo a que está relacionado não é 3-colorível. A medição não foi implementada; porém, ela poderá ser feita com base na seção 2.3.8.
O autoestado |11> não possui cor correspondente. Sendo assim, as linhas 7 à 10 transformam os autoestados |11> em autoestados |00> . O trecho principal do programa encontra-se da linha 11 à linha 15.
O grafo é válido quando todas as arestas forem válidas.
A forma convencional de programar baseia-se no desenvolvimento da solução manipulando-se a informação de entrada até obter-se a saída esperada. Em máquinas quânticas ou moleculares, a forma de programar mais comum é simplesmente gerar e testar todas as soluções possíveis em paralelo e selecionar a solução válida se ela existir. Na computação quântica ou molecular, o trabalho do projetista de software é construir um conjunto de operações que verifica a validade de uma solução. Muitos algoritmos construidos para máquinas quânticas e moleculares podem ser resumidos da forma que segue:
Gera todas as possíveis entradas;
Seleciona a entrada que atenda a uma condição determinada;
De forma análoga, o algoritmo que testa se um grafo é 3-colorível pode ser resumido à forma que segue:
Gera todas as colorações possíveis para o grafo em questão usando somente três cores;
Seleciona os grafos que não apresentam vértices adjacentes com as mesmas cores;
Conclui-se que a maneira de programar um computador quântico é muito semelhante a maneira de programar um computador biológico.
Em relação às máquinas clássicas, de acordo com o que estudou-se na seção 4.3, as máquinas quânticas e biológicas podem resolver certos problemas de forma extremamente rápida; porém, as máquinas quânticas e biológicas não tem poder computacional superior ao poder computacional da máquina de Turing.
No capítulo 3, observa-se a dificuldade de se fazer a operação lógica AND em QCL. Entendendo que futuros estudantes e cientistas enfrentarão o mesmo problema, o autor do presente trabalho implementou uma pequena biblioteca chamada boolean.qcl que facilita enormemente o trabalho despendido para implementação de funções lógicas.
No presente anexo, serão apresentadas as funções quânticas quAnd, quNand, quOr, quNor, quXor, quEqual, quTest, quVectNAnd, quVectOr, quVectNOr e o operador quPICPhase.
Para efeito de entendimento, refere-se a registrador limpo o registrador quântico que apresenta somente um autoestado com todos os seus bits em zero do tipo |000...>. Em todos os exemplos que serão apresentados no corrente capítulo, a biblioteca boolean.qcl foi previamente incluida com o comando include “boolean.qcl”. Além disso, os qubits relacionados a saída das funções serão sempre grafados em negrito.
Declaração: qufunct quAnd(qureg a,quconst b, quconst c)
Registradores de entrada: b e c.
Registrador de saída: a preferencialmente limpo.
Semântica: o registrador a recebe o resultado da operação b and c. Todos os registradores devem ter o mesmo número de qubits.
Exemplo: serão declarados os três registradores x,y e r com 2 qubits cada. Após, será forçada a superposição linear de autoestados sobre x e y. Então, será executada a função quAnd com entradas x e y e saída em r.
qcl1> qureg x[2]
qcl1> qureg y[2]
qcl1> qureg r[2]
qcl1> Mix(x&y)
qcl1> quAnd(r,x,y)
[6/6] 0.25 |000000> + 0.25 |001000> + 0.25 |000100> + 0.25 |001100> +
0.25 |000010> + 0.25 |101010> + 0.25 |000110> + 0.25 |101110> +
0.25 |000001> + 0.25 |001001> + 0.25 |010101> + 0.25 |011101> +
0.25 |000011> + 0.25 |101011> + 0.25 |010111> + 0.25 |111111>
Declaração: qufunct quNand(qureg a,quconst b, quconst c)
Registradores de entrada: b e c.
Registrador de saída: a preferencialmente limpo.
Semântica: o registrador a recebe o resultado da operação not (b and c). Todos os registradores devem ter o mesmo número de qubits.
Exemplo: será executada a função quNand com entradas x e y e saída em r.
qcl1> qureg x[2]; qureg y[2]; qureg r[2]
qcl1> Mix(x&y)
qcl1> quNand(r,x,y)
[6/6] 0.25 |110000> + 0.25 |111000> + 0.25 |110100> + 0.25 |111100> +
0.25 |110010> + 0.25 |011010> + 0.25 |110110> + 0.25 |011110> +
0.25 |110001> + 0.25 |111001> + 0.25 |100101> + 0.25 |101101> +
0.25 |110011> + 0.25 |011011> + 0.25 |100111> + 0.25 |001111>
Declaração: qufunct quOr(qureg a,quconst b, quconst c)
Registradores de entrada: b e c.
Registrador de saída: a preferencialmente limpo.
Semântica: o registrador a recebe o resultado da operação (b or c). Todos os registradores devem ter o mesmo número de qubits.
Exemplo: será executada a função quOr com entradas x e y e saída em r.
qcl1> qureg x[2]; qureg y[2]; qureg r[2]
qcl1> Mix(x&y)
qcl1> quOr(r,x,y)
[6/6] 0.25 |000000> + 0.25 |101000> + 0.25 |010100> + 0.25 |111100> +
0.25 |100010> + 0.25 |101010> + 0.25 |110110> + 0.25 |111110> +
0.25 |010001> + 0.25 |111001> + 0.25 |010101> + 0.25 |111101> +
0.25 |110011> + 0.25 |111011> + 0.25 |110111> + 0.25 |111111>
Declaração: qufunct quNor(qureg a,quconst b, quconst c)
Registradores de entrada: b e c.
Registrador de saída: a preferencialmente limpo.
Semântica: o registrador a recebe o resultado da operação not (b or c). Todos os registradores devem ter o mesmo número de qubits.
Exemplo: será executada a função quNor com entradas x e y e saída em r.
qcl1> qureg x[2]; qureg y[2]; qureg r[2]
qcl1> Mix(x&y)
qcl1> quNor(r,x,y)
[6/6] 0.25 |110000> + 0.25 |011000> + 0.25 |100100> + 0.25 |001100> +
0.25 |010010> + 0.25 |011010> + 0.25 |000110> + 0.25 |001110> +
0.25 |100001> + 0.25 |001001> + 0.25 |100101> + 0.25 |001101> +
0.25 |000011> + 0.25 |001011> + 0.25 |000111> + 0.25 |001111>
Declaração: qufunct quXor(qureg a,quconst b)
Registradores de entrada: a e b.
Registrador de saída: a .
Semântica: o registrador a recebe o resultado da operação (a xor b). Todos os registradores devem ter o mesmo número de qubits.
Exemplo: a função quXor(r,x) copia o conteúdo de r em x. A execução da função quXor(r,y) resulta que em r residirá o resultado de x xor y.
qcl1> qureg x[2]; qureg y[2]; qureg r[2]; Mix(x&y)
qcl1> quXor(r,x)
qcl1> quXor(r,y)
[6/6] 0.25 |000000> + 0.25 |101000> + 0.25 |010100> + 0.25 |111100> +
0.25 |100010> + 0.25 |001010> + 0.25 |110110> + 0.25 |011110> +
0.25 |010001> + 0.25 |111001> + 0.25 |000101> + 0.25 |101101> +
0.25 |110011>
+ 0.25 |011011> + 0.25 |100111> + 0.25 |001111>
Declaração: qufunct quEqual(qureg a,quconst b)
Registradores de entrada: a e b.
Registrador de saída: a .
Semântica: o registrador a recebe o resultado da operação not (a xor b). Todos os registradores devem ter o mesmo número de qubits.
Exemplo: a função quXor(r,x) copia o conteúdo de r em x. A execução da função quEqual(r,y) resulta que em r residirá o resultado de not( x xor y ).
qcl1> qureg x[2]; qureg y[2]; qureg r[2]; Mix(x&y)
qcl1> quXor(r,x)
qcl1> quEqual(r,y)
[6/6] 0.25 |110000> + 0.25 |011000> + 0.25 |100100> + 0.25 |001100> +
0.25 |010010> + 0.25 |111010> + 0.25 |000110> + 0.25 |101110> +
0.25 |100001> + 0.25 |001001> + 0.25 |110101> + 0.25 |011101> +
0.25 |000011>
+ 0.25 |101011> + 0.25 |010111> + 0.25 |111111>
Declaração: qufunct quTest(qureg f, qureg a,quconst b)
Registradores de entrada: a e b com o mesmo número de qubits.
Registrador de saída: f preferencialmente limpo com 1 qubit.
Semântica: o registrador a recebe o resultado do teste (a = b).
Exemplo: a função quTest(r,x,y) testa se ( x = y ) pondo o resultado em r .
qcl1> qureg x[2]; qureg y[2]; qureg r[1]
qcl1> Mix(x)
qcl1> quTest(r,x,y)
[5/6] 0.25 |010000> + 0.25 |001000> + 0.25 |000100> + 0.25 |001100> +
0.25 |000010> + 0.25 |011010> + 0.25 |000110> + 0.25 |001110> +
0.25 |000001> + 0.25 |001001> + 0.25 |010101> + 0.25 |001101> +
0.25 |000011> + 0.25 |001011> + 0.25 |000111> + 0.25 |011111>
Declaração: quPICPhase(qureg x,int n)
Entrada: registrador x e inteiro n.
Registrador de saída: x.
Semântica: rotaciona PI radianos ( o que equivale a 180 graus ou multiplicar por -1 ) da amplitude de probabilidade do autoestado em que x=n. O nome do operador deve lembrar “ quantum PI Conditional Phase “.
Exemplo: os autoestados que sofreram mudança de fase forma grafados em negrito.
qcl1> qureg x[2]; qureg y[2]; Mix(x); quXor(y,x); Not(y)
[4/4] 0.5 |1100> + 0.5 |0110> + 0.5 |1001> + 0.5 |0011>
qcl1> quPICPhase(y,2);
[4/4] 0.5 |1100> + 0.5 |0110> + -0.5 |1001> + 0.5 |0011>
qcl1> quPICPhase(y,3);
[4/4] -0.5 |1100> + 0.5 |0110> + -0.5 |1001> + 0.5 |0011>
qcl1> quPICPhase(x,2);
[4/4] -0.5 |1100> + -0.5 |0110> + -0.5 |1001> + 0.5 |0011>
qcl1> quPICPhase(x,3);
[4/4] -0.5 |1100> + -0.5 |0110> + -0.5 |1001> + -0.5 |0011>
Declaração: qufunct quVectNAnd(qureg a,quconst b)
Registrador de entrada: b com qualquer número de qubits.
Registrador de saída: a preferencialmente limpo com 1 qubit.
Semântica: o registrador a recebe o resultado da operação lógica not( b[0] and b[1] and b[2] and ... and b[n]). a recebe o resultado da operação NAND sobre o vetor de bits b.
Exemplo:
qcl1> qureg x[3]; qureg y[1]; Mix(x)
qcl1> quVectNAnd(y,x)
qcl1> dump x&y
: SPECTRUM x&y: |............................3210>
0.125 |0111> + 0.125 |1000> + 0.125 |1001> + 0.125 |1010> +
0.125 |1011> + 0.125 |1100> + 0.125 |1101> + 0.125 |1110>
Declaração: qufunct quVectNOr(qureg a,quconst b)
Registrador de entrada: b com qualquer número de qubits.
Registrador de saída: a preferencialmente limpo com 1 qubit.
Semântica: o registrador a recebe o resultado da operação lógica not( b[0] or b[1] or b[2] or ... or b[n]).
Exemplo:
qcl1> quVectNOr(y,x)
qcl1> dump x&y
: SPECTRUM x&y: |............................3210>
0.125 |0001> + 0.125 |0010> + 0.125 |0011> + 0.125 |0100> +
0.125 |0101> + 0.125 |0110> + 0.125 |0111> + 0.125 |1000>
Declaração: qufunct quVectOr(qureg a,quconst b)
Registrador de entrada: b com qualquer número de qubits.
Registrador de saída: a preferencialmente limpo com 1 qubit.
Semântica: o registrador a recebe o resultado da operação lógica ( b[0] or b[1] or b[2] or ... or b[n]).
Exemplo:
qcl1> qureg x[3]; qureg y[1]; Mix(x)
qcl1> quVectOr(y,x)
qcl1> dump x&y
: SPECTRUM x&y: |............................3210>
0.125 |0000> + 0.125 |1001> + 0.125 |1010> + 0.125 |1011> +
0.125 |1100> + 0.125 |1101> + 0.125 |1110> + 0.125 |1111>
O problema SAT ( do inglês “ satisfiability ” ) tem uma enorme importância para a ciência da computação tendo em vista que toda uma classe de problemas é polinomialmente transformável no problema SAT. No presente anexo, apresenta-se uma implementação em QCL que resolve uma determinada instância do problema SAT. A implementação apresentada aqui pode ser facilmente modificada para resolver qualquer instância do problema SAT.
Todo problema que é resolvido por um algoritmo que despende tempo de execução polinomialmente proporcional ao tamanho de sua entrada em uma máquina clássica é dito problema tratável. Os problemas tratáveis são resolvidos por algoritmos que apresentam ordem de tempo de execução de O(P(n)).
Por outro lado, os problemas intratáveis são os problemas em que o tempo de execução não pode ser descrito por um polinômio em função do tamanho de sua entrada. Os problemas intratáveis são conhecidos também por problemas NP. Em geral, os problemas intratáveis não são praticamente solúveis para entradas muito grandes.
Por fim, os problemas NP-completos são problemas NP que são polinomialmente transformáveis no problema SAT. Sendo assim, se por acaso for descoberto um único algoritmo que resolve de forma eficiente um problema NP-completo, para todo problema NP-completo existente haverá um algoritmo eficiente que o resolve. Não existem algoritmos eficientes conhecidos para máquinas seqüenciais que resolvem problemas NP-completos.
O problema SAT é decidir se dada uma função lógica S na forma normal conjuntiva (FNC) é verdadeira para uma entrada qualquer. Em outras palavras, o problema SAT é decidir se existe uma entrada para a função lógica S que torne a função S verdadeira. A FNC é produto de termos máximos ou produto de somas. Segue um exemplo de expressão lógica na FNC:
( ( a or not(b)) and ( not(a) or b))
No presente tópico, é apresentado somente a simplificação do trecho principal do programa. A implementação completa pode ser encontrada no arquivo sat.qcl que se encontra no CD-ROM anexo. Segue a simplificação do trecho principal:
Mix(q); // prepara superposição
BooleanFunction(q,f); // calcula a função lógica
CPhase(pi,f); // nega o autoestado que valida a função
!BooleanFunction(q,f);// reverte a função lógica
diffuse(q); // amplifica a probabilidade das soluções
measure q,x; // mede a saída em x
O número das linhas foi incluído apenas para facilitar o entendimento.
Na linha 1, o registrador q recebe a superposição linear de todos as entradas possíveis para a função lógica BooleanFunction.
Na linha 2, todas as entradas possíveis são processadas em paralelo pela função BooleanFunction. O registrador f (flag) recebe 1 para os autoestados (entradas) que apresentam soluções verdadeiras.
Na linha 3, todos os autoestados que correspondem a entradas verdadeiras sofrem rotação de 180 graus em suas amplitudes de probabilidade.
Na linha 4, amplifica as probabilidades dos autoestados que representam soluções.
Na linha 5, mede não deterministicamente uma entrada.
|
[ADL 94] |
ADLEMAN, Leonard M. Molecular Computation of Solutions of Combinatorial Problems. Science v.266, p.1021-1024, Nov.1994. |
|
[ADL 96] |
ADLEMAN, Leonard M. On Constructing a Molecular Computer. DNA Based Computers, American Mathematical Society, 1996, p. 1-21. |
|
[ADL 2000] |
ADLEMAN, Leonard M. Leonard Adleman Home Page At USC. Disponível por WWW em http://www-scf.usc.edu/~pwkr/adleman-home.html (4, janeiro, 2001) |
|
[AHA 98] |
AHARONOV, Dorit. Introduction to Quantum Computing. Annual Reviews of Computational Physics VI. Edited by Dieterich Stauffer. World Scientific, 1998 |
|
[BAR 95] |
BARENCO, Adriano; BENNET, Charles; CLEVE, Richard; DIVICENZO, David P.; MARGOLUS, Norman; SHOR, Peter; SLEATOR, Tycho; SMOLIN, John A.; WEINFURTER, Harald. Elementary gates for quantum computation. Phys. Rev. A, v. 52, n. 5, p. 3457 - 3467, Nov. 1995. |
|
[BAR 96] |
BARENCO, Adriano. Quantum physics and computers. Contemporary Physics. v. 38, p. 357 - 389, 1996. |
|
[BER 93] |
BERNSTEIN, E.; VAZIRANI,U. Quantum complexity theory. 25th ACM Symposium on the Theory of Computation. New York: ACM Press, p. 11-20, 1993. |
|
[BUC 2000] |
BUCHANAN, Mark. The Quantum Computers Inside us. New Scientist. v. 166, n.2234, p. 22-24, Abr. 2000. |
|
[BOY 98] |
BOYER, Michel; BRASSARD, Gilles , Høyer, Peter; TAPP, Alain. Tight bounds on quantum searching. . Fortschritte Der Physik, Special issue on quantum computing and quantum cryptography, v. 46, n. 4-5, p. 493-505, Jun. 1998. |
|
[DEU 85] |
DEUTSCH, David. Quantum Theory, the Church-Turing principle and the universal quantum computer. Proceedings of Royal Society of London, A400, p.97-117, 1985. |
|
[EIG 97] |
EIGEN, Manfred. O que restará da biologia do século XX? “O que é vida” 50 anos depois. São Paulo, Editora UNESP, p. 13-33, 1997. |
|
[FEL 88] |
FELTRE, Ricardo. Química V.3, Editora Moderna, São Paulo, 1988. p. 347-356. |
|
[FEY 82] |
FEYNMAN, Richard P. Simulating Physics with Computers. International Journal of Theoretical Physics. v. 21 n. 6-7, p. 467-488, 1982. |
|
[GRO 96] |
GROVER, Lov K. A fast quantum mechanical algorithm for database search. Proceedings STOC, Philadelphia, p. 212- – 219, 1996 |
|
[HAE 92] |
HAEFNER, Klaus. Evolution of Information Processing Systems . Springer-Verlag. Berlin, 1992. p.1-46. |
|
[HAM 87] |
HAMEROFF, Stuart R. Ultimate Computing. Elsevier Science Publishers. Amsterdam, 1987. |
|
[HAY 98] |
HAYES, Brian. The Invention of the Genetic Code. American Scientist. Jan.-Fev. , 1998 disponível por WWW em http://www.amsci.org/amsci/issues/Comsci98/compsci9801.html (4, janeiro, 2001) |
|
[HAW 88] |
HAWKING, Stephen W. Uma Breve História do Tempo, editora Rocco Ltda, São Paulo, 1988.p. 63-70. |
|
[JAM 84] |
JAMES, Mike. Inteligência Artificial em BASIC. Editora Campus, 1984. p.10-58. |
|
[KLE 95] |
KLEIN, A. Is Quantum Mechanics Relevant To Understanding Consciousness? - A Review of Shadows of the Mind by Roger Penrose. PSYCHE, 2(2), Abr. 1995.Disponível por WWW em http://psyche.cs.monash.edu.au/v2/psyche-2-03-klein.html (4, janeiro, 2001) |
|
[NOR 81] |
NORA, James J.; FRASER, Clarke. Genética Médica. Guanabara Koogan S. A. , Rio de Janeiro, 1991 |
|
[OME 88] |
ÖMER, Bernhard. A Procedural Formalism for Quantum Computers. Disponível por WWW em http://tph.tuwien.ac.at/~oemer/qcl.html . (4, janeiro, 2001) |
|
[OME 2000] |
ÖMER, Bernhard. Quantum Programming in QCL. Disponível por WWW em http://tph.tuwien.ac.at/~oemer/qcl.html . (4, janeiro, 2001) |
|
[OPE 2000] |
Open Qubit Quantum Computing. Disponível por WWW em |
|
[PAT 2000] |
PATEL, Apoorva. Quantum Algorithms and the Genetic Code. Invited lectures presented at the Winter Institute on “ Foundations of Quantum Theory and Quantum Optics“, p.1-13, Jan. 2000. |
|
PENROSE, Roger. A Mente Nova do Rei, editora Campus Ltda, Rio de Janeiro, 1991. | |
|
PENROSE, Roger. Shadows of the Mind. Oxford University Press. New York, 1994. p. 101. | |
|
[REG 87] |
REGIS, Ed. Who's Got Einstein's Office?, Addison-Wesley, 1987 ou disponível por WWW em http://www.stephenwolfram.com/about-sw/interviews/87-einstein/text.html . (4, janeiro, 2001) |
|
[SAG 77] |
SAGAN, Carl. The Dragons of Eden - Speculations on the evolution of Human Intelligence, The Ballantine Publishing Group, Toronto, 1977 |
|
SAGAN, Carl. COSMOS. Livraria Francisco Alves Editora S.A., Rio de Janeiro, 1983. p.23-42. | |
|
[SIM 94] |
SIMON, Daniel. On The Power of Quantum Computation. Proceedings of the 35th IEEE Symposium on Foundations of Computer Science, p 124 -134. IEEE, 1994. |
|
[STA 95] |
STAPP, Henry P. Why classical Mechanics Cannot Naturally Accommodate Consciousness but Quantum Mechanics Can. PSYCHE, 2(2), Abr. 1995. Disponível por WWW em http://psyche.cs.monash.edu.au/v2/psyche-2-05-stapp.html (4, janeiro, 2001) |
|
[WIL 97] |
WILLIAMS, Colin P. CLEARWATER, Scott H. Explorations in QUANTUM COMPUTING. Springer-Verlag. New York,1997. |